
不用拍的广告片?深度拆解美团闪购AIGC营销新案例
不用拍的广告片?深度拆解美团闪购AIGC营销新案例唯“快”不破的美团闪购,这次搞了一波AIGC技术流营销。先说结论,从已经公开的视频来看,他们算是终于回答了一个近几年被反复提起、却很少被真正解决的问题——在当下这个时代,品牌方到底该怎么用AIGC。
来自主题: AI资讯
8060 点击 2026-01-16 14:28
唯“快”不破的美团闪购,这次搞了一波AIGC技术流营销。先说结论,从已经公开的视频来看,他们算是终于回答了一个近几年被反复提起、却很少被真正解决的问题——在当下这个时代,品牌方到底该怎么用AIGC。

本次发布的核心——AIMesh,正是这场架构创新的集大成者。 它被定义为面向「AI工厂」的数据与内存网,核心思路是用一套「三网合一」的柔性网络,替代传统僵化的存储架构。
项目缘起:从 0 到 1 的 PromptTuner 诞生之路 随着大模型技术的普及,AI 交互已成为日常工作的重要组成部分。然而,如何写出高质量的提示词(Prompt)却成为普通用户面临的新挑战。

MemGovern团队 投稿 量子位 | 公众号 QbitAI 人类程序员碰到棘手bug通常会上网查询前辈经验。 当前AI虽然开始具备联网搜索能力,但仍不能很好地从网络经验中获取修复bug的能力。 让
近日,德国物理学家、百万粉丝科普博主Sabine Hossenfelder在一则视频中,抛出了一个让学术界「脊背发凉」的观点:三年内,我们所熟悉的科学研究将不复存在。但AI能力的进化速度,远远超出人类预期。
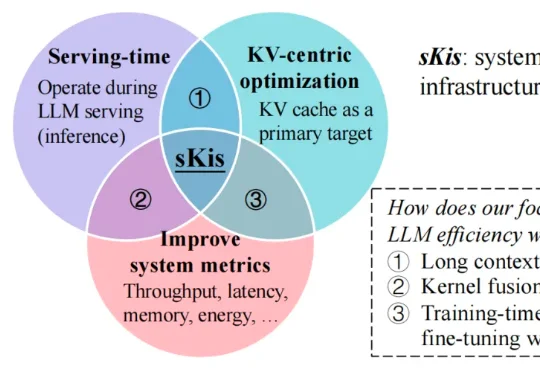
近期,来自墨尔本大学和华中科技大学的研究者们发布了一篇深度综述,从 MLSys 的思维出发,用一套新颖的「时间 - 空间 - 结构」系统行为视角对 KV cache 优化方法进行了系统性梳理与深入分析,并将相关资源整理成了持续维护的 Awesome 资源库,方便研究者与从业人员快速定位与落地。
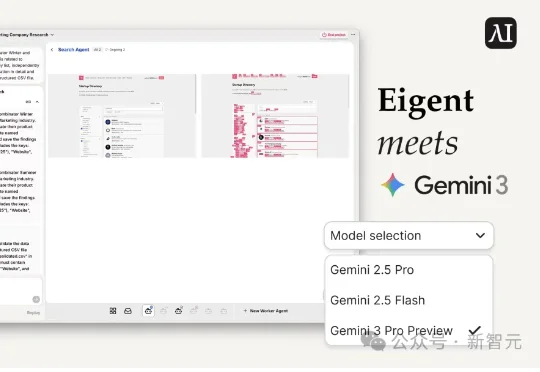
Claude Cowork一出,直接砸碎了Guohao Li的创业梦,华人学者反手把分布式多智能体项目全开源!代码朋克的怒火,已点燃整个AI社区。下一代Agent的战争,就此打响。
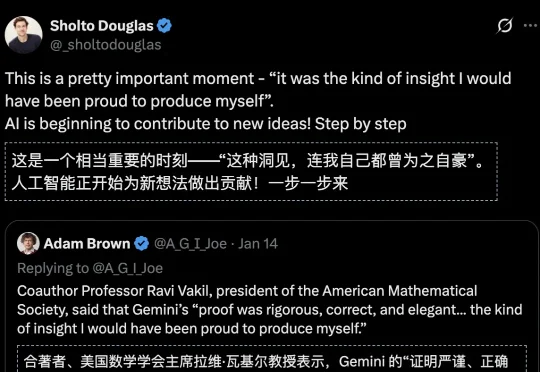
数学奇点初现!Gemini攻克全新数学定理,斯坦福大牛惊呼「想出来能吹一辈子」;陶哲轩预言数学家+AI共生未来;Grok发现黎曼猜想新的隐蔽通道……
2026年真正爆点,必将是「超级组织」崛起。AI开始进入团队重写工作流,自动执行共享记忆,与团队协同让效率原地起飞。你的下一位同事,可能是AI。

昨晚,超级超级开心的邀请了我的两位好朋友、也是我的两位偶像海辛和阿文,来我的视频号做了一场直播。