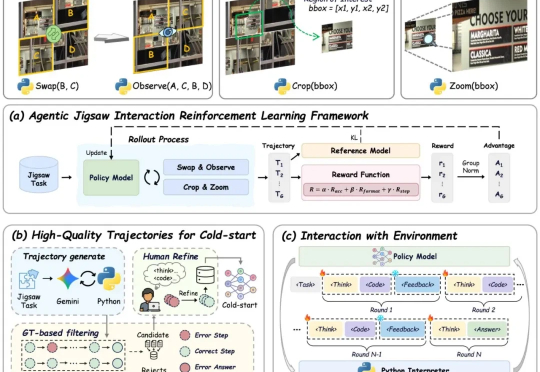
敏捷开发「BMAD」也推出了Agent Skills,CC直接用| 斩获2.6万star
敏捷开发「BMAD」也推出了Agent Skills,CC直接用| 斩获2.6万starBMAD推出了: BMAD Method v6 for Claude Code skills。这不仅仅是一套Skills集,它是一套将敏捷开发方法论(Agile Methodology)与AI原生能力深度融合的工程框架。它将Claude Code从一个“更聪明的编辑器”转变为一支具备9种专业角色、15种标准工作流的“全栈敏捷开发团队”。
来自主题: AI资讯
9696 点击 2025-12-30 15:17