
葬AI基准测试更新:Seed 2.1 Pro急需摆脱平庸的重力
葬AI基准测试更新:Seed 2.1 Pro急需摆脱平庸的重力豆包产品无敌,但Seed模型一直不温不火,大伙对它的印象就两个: 工资高,隔三差五就有千万年包上亿年包新闻,也不知道真假;多模态,但编程能力不太行。
来自主题: AI资讯
6784 点击 2026-06-29 09:19
 搜索
搜索
豆包产品无敌,但Seed模型一直不温不火,大伙对它的印象就两个: 工资高,隔三差五就有千万年包上亿年包新闻,也不知道真假;多模态,但编程能力不太行。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
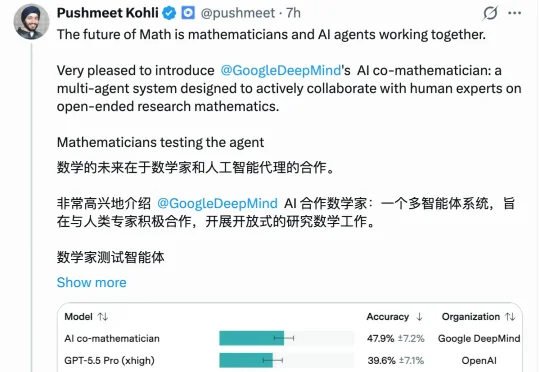
群论领域几十年无解的第21.10号问题,被牛津数学家Marc Lackenby用谷歌一个新系统破解了。过程也很有意思:AI第一次给出的证明是错的,被系统里的审查Agent揪出了漏洞。
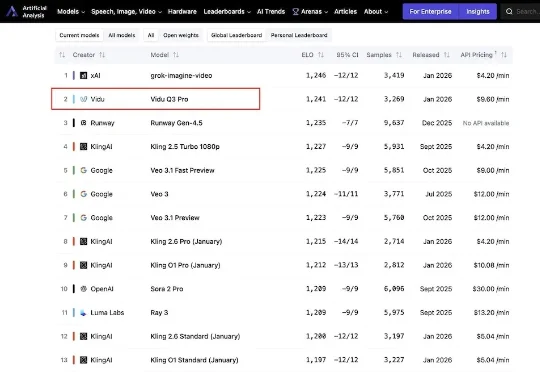
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。

我们经常在一些对比 AI 性能的测试中,看到宣称基础模型在自然语言理解、推理或编程任务等性能超人类的相关报道。

基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。
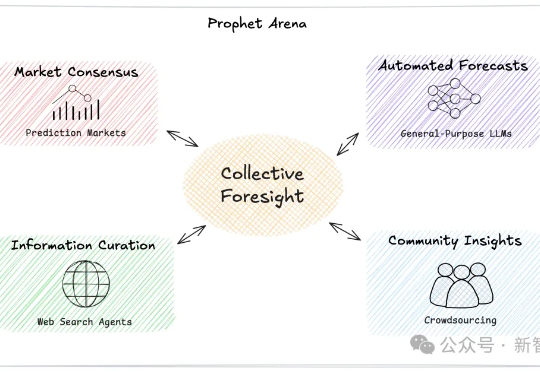
AI能像科幻电影中的先知一样预测未来吗?一个名为「Prophet Arena」的全新基准测试,正通过预测真实世界事件来评估AI的「预言」能力。
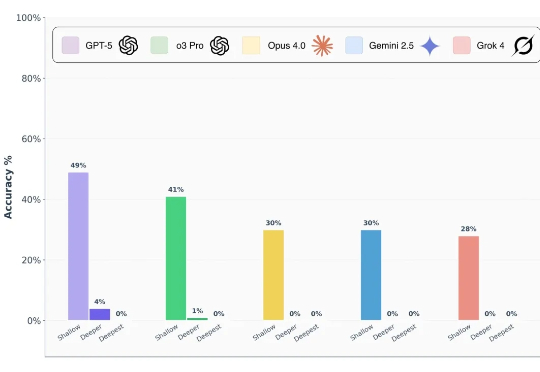
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?

大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力。为了更好的开发下一代向量模型和重排器,我们首先需要一个能评测模型在视觉复杂文档能力的基准集。