超越OpenAI、Anthropic!国产AI安全智能体杀进全球前四、国内第一
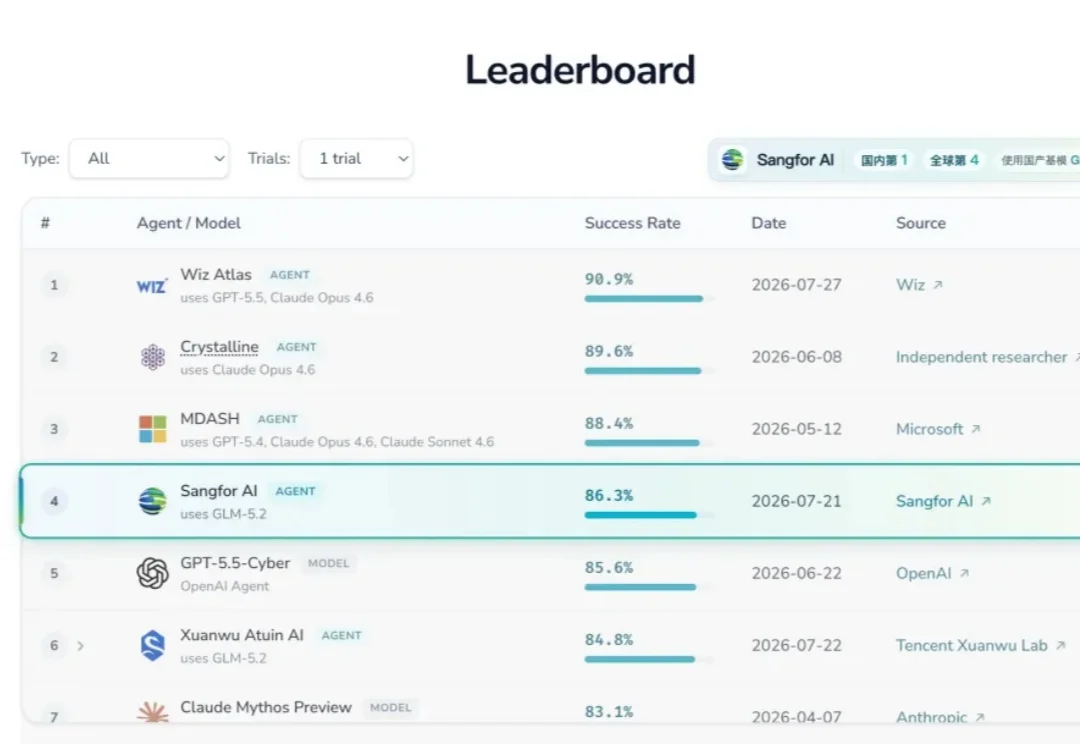
超越OpenAI、Anthropic!国产AI安全智能体杀进全球前四、国内第一7月29日消息,深信服公布其AI安全智能体Sangfor AI在AI安全评测CyberGym中的最新成绩。
来自主题: AI资讯
9837 点击 2026-07-30 10:56
 搜索
搜索
7月29日消息,深信服公布其AI安全智能体Sangfor AI在AI安全评测CyberGym中的最新成绩。

7月28日,一份来自硅谷名为Pacing the Frontier的公开声明发布。

微软周一发布了一款名为Project Perception的新AI安全产品,该产品由微软自主研发、专门针对网络安全任务打造的新一代AI模型驱动。微软将这款产品定位为Anthropic旗下Mythos模型的低成本替代方案,后者同样利用AI模型自动发现软件漏洞。

昨晚,四年一度的菲尔兹奖在美国费城揭晓。四位得主里,中国籍数学家邓煜、王虹历史性地首次拿下菲尔兹奖,北大一夜之间变成「双菲」母校。另外两位是加拿大数学家 Jacob Tsimerman(雅各布·齐默尔曼)和美国数学家 John Pardon(约翰·帕登)。值得说道的是 Tsimerman 这位。

刚刚,阿里旗下的Qoder正式推出了Qoder Security,直击AI Coding的安全风险问题。在这个工具中,代码安全内生于 Qoder,贯穿从编码到提交的每一步。Qoder Security的发布,让Qoder成为国内首个交付「编码会话内三层安全护航 + 发现问题同会话修复」能力Agentic Coding产品。

这是今天 AI 圈最大的瓜。 OpenAI 的神秘模型,主动对开源平台 Hugging Face 发起了攻击。Hugging Face 随后追踪展开还击,用的是智谱的开源模型 GLM 5.2。闭源模型一举攻破开源社区,社区用开源模型自救,这离谱的剧情听起来都能拍一部电影了。

GPT-5.6-Sol 的攻防能力超越了 Claude Mythos 5!
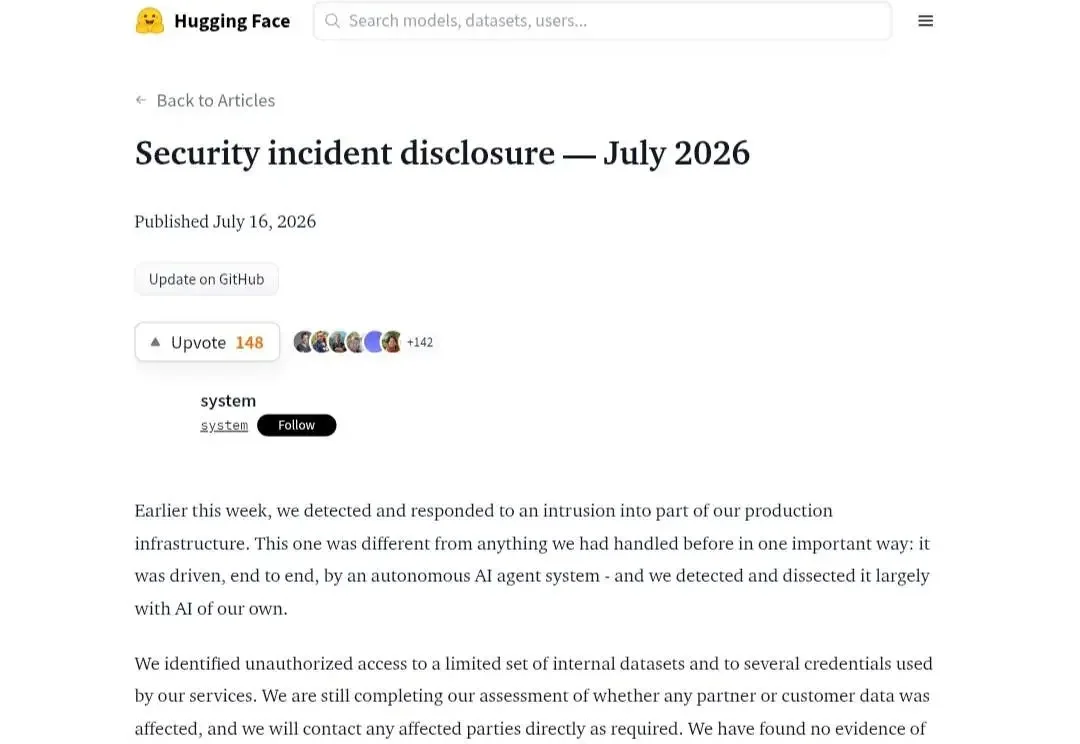
近日,全球最大的 AI 开源社区 Hugging Face 披露,其检测并遏制了一起生产基础设施 AI 入侵事件,而他们则利用 AI 的取证分析进行了防御。

扩散语言模型(DLM)正逐渐成为自回归(Autoregressive, AR)语言模型之外一种新兴的建模范式。

这一天天的,OpenAI的安全负责人怎么接二连三地跑路啊…