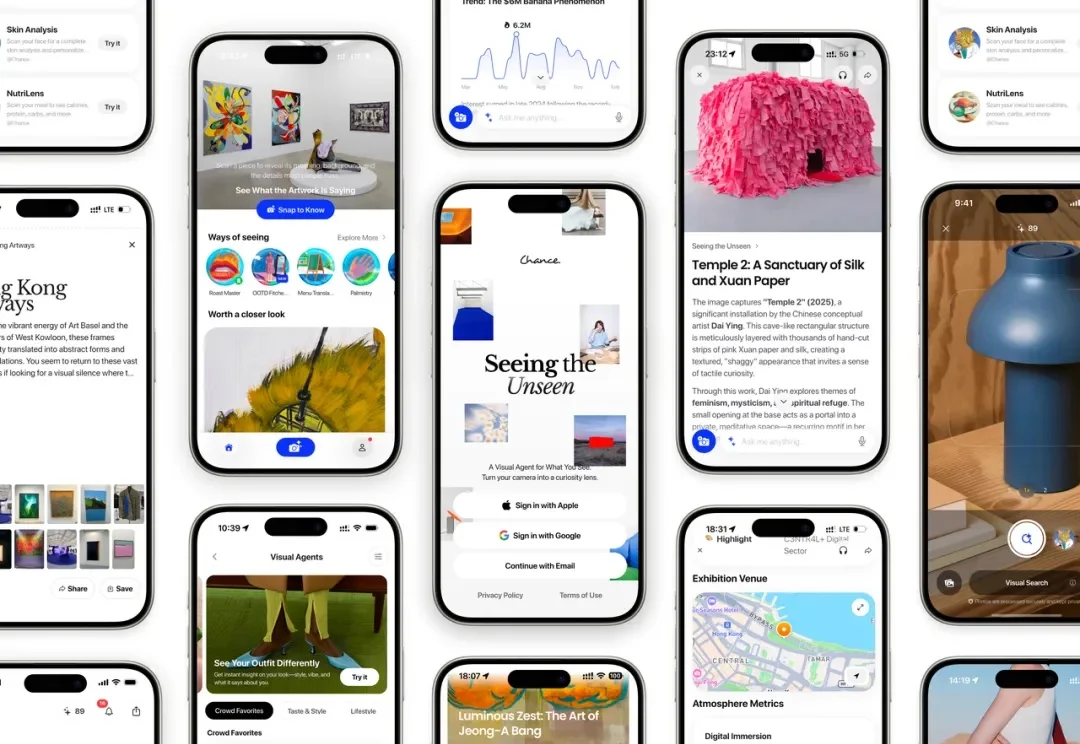
深度|10人团队登顶视觉推理榜,Chance AI 超过GPT、Gemini和人类专家
深度|10人团队登顶视觉推理榜,Chance AI 超过GPT、Gemini和人类专家过去两年,多模态模型的竞争看起来像一场“造眼睛”的竞赛:更高的图像分辨率、更多的视觉 token、更大的模型,以及更昂贵的训练。行业似乎默认,只要第一次看得足够清楚,AI 就能从“看见”抵达“洞见”。
来自主题: AI资讯
9938 点击 2026-07-30 11:34
 搜索
搜索
过去两年,多模态模型的竞争看起来像一场“造眼睛”的竞赛:更高的图像分辨率、更多的视觉 token、更大的模型,以及更昂贵的训练。行业似乎默认,只要第一次看得足够清楚,AI 就能从“看见”抵达“洞见”。

扩散模型已经越来越会「画」,却还远没有学会「守住要求」。决定系统是否可靠的,已不再只是画质,而是生成结果能否持续遵守条件、维持状态,并符合人类与现实世界的基本标准。
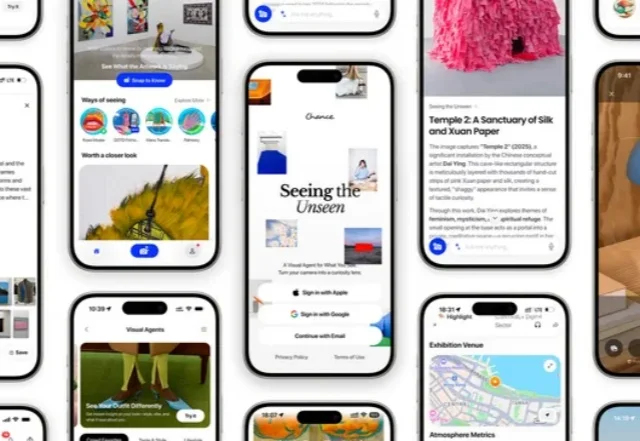
一款没有输入框的AI应用,正在北美高校悄悄走红。
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。

创始人张霄昨天,2026年4月23日,宣布融资2300万美元,也成立了Collov Labs Research,资金用于扩充研究团队和加速视觉AI系统研发,而非单纯的商业扩张。

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。
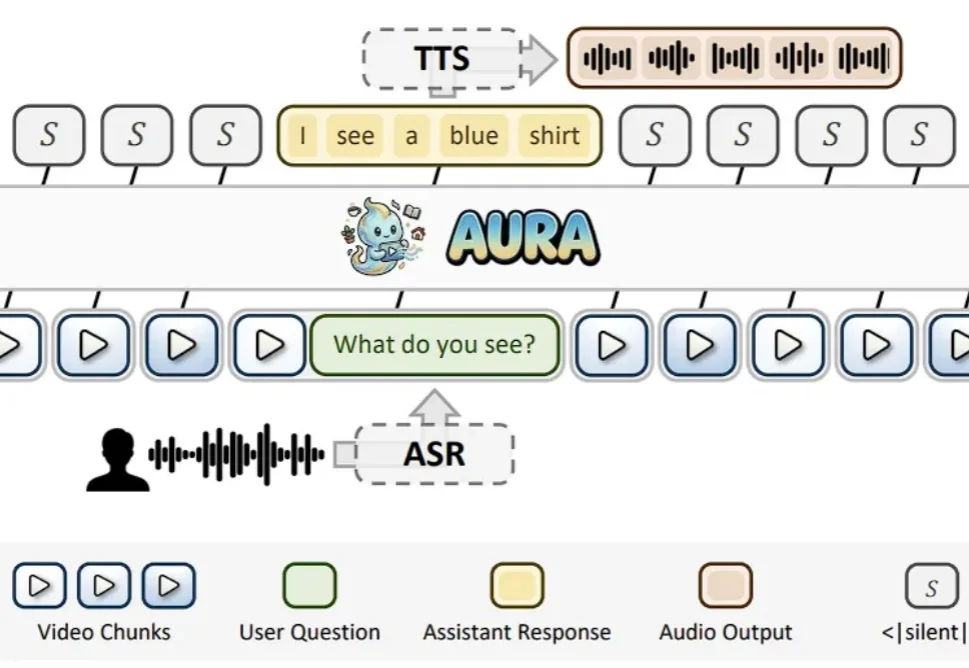
近年来,视频多模态大模型(VideoLLM)发展迅猛,在视频描述、视频问答、时序定位等任务上不断刷新性能上限。随着模型能力持续增强,业界也开始思考一个更重要的问题:视频大模型能不能不再只是 “看完一段视频再回答”,而是真正进入实时世界,持续观察、实时理解,并在关键时刻主动给出反馈?

激进投资者艾略特投资管理公司已持有Pinterest 价值 10 亿美元股份,该公司以积极参与企业决策而闻名。该机构首次投资这家社交平台是在 2022 年。
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。

BiCo是一种创新的AI视觉内容生成方法,能灵活组合图像和视频中的视觉概念,实现可控编辑。它通过分层绑定器、多样化与吸收机制、时间解耦策略等技术创新,解决了现有方法在概念提取和组合上的问题,让AI真正理解并融合视觉元素。