
DeepSeek V4第一天就能跑!本地Token生产平台来了
DeepSeek V4第一天就能跑!本地Token生产平台来了“AI新物种”企业级Token生产平台TokenBox™。
来自主题: AI资讯
6107 点击 2026-06-03 09:27
 搜索
搜索
“AI新物种”企业级Token生产平台TokenBox™。

今天,OpenAI 正式揭晓了 DeployCo:OpenAI 部署公司

昨天晚上,OpenAI 宣布推出了 OpenAI 部署公司(OpenAI Deployment Company),目标是帮助企业构建和部署 AI。该公司由 OpenAI 持有多数股权并进行控制,汇集了 19 家领先的投资机构、咨询公司和系统集成商,协助各类组织将前沿 AI 投入生产应用,从而在业务上产生实际影响
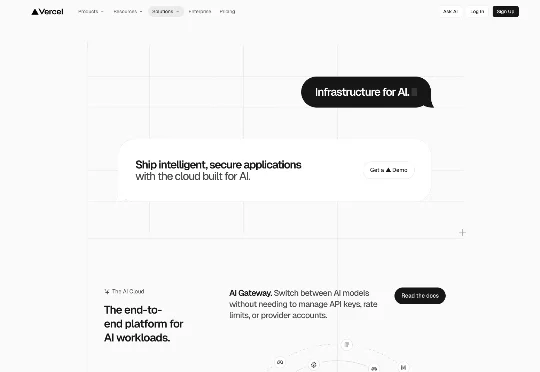
如果你只把 Vercel 理解为“一个部署前端项目的工具”,那你大概只看到了它的 10%。Vercel 现在的估值是 93 亿美元,GAAP 年化收入已达 3.4 亿,同比增长 84%。这个数字放在 2026 年的 AI 公司里不算最耀眼的,但绝对是最不可思议的——因为它的起点不是 AI,而是“部署”。
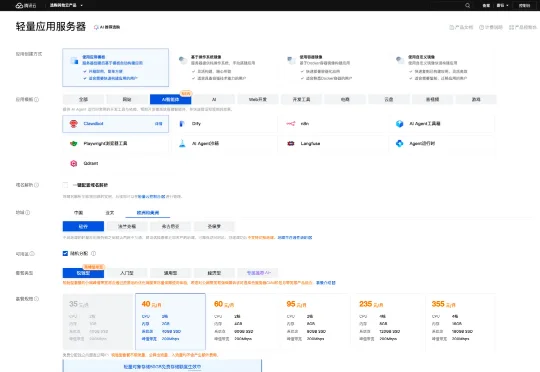
相较于筹备实体硬件涉及的购置成本、时间及后续电费,云服务器显然是更快捷、经济的选择。而轻量应用服务器 Lighthouse 具备开箱即用、高性价比及免运维的特性,与 Clawdbot 的部署需求完美契合。

2023 年,三星公司在接入 ChatGPT 不久之后,接连发生数起内部机密泄露事件。事件起因是三星员工将半导体设备参数、产品源代码和生产良率等商业机密直接输入对话系统,导致敏感信息被录入 ChatGPT 的训练数据库。
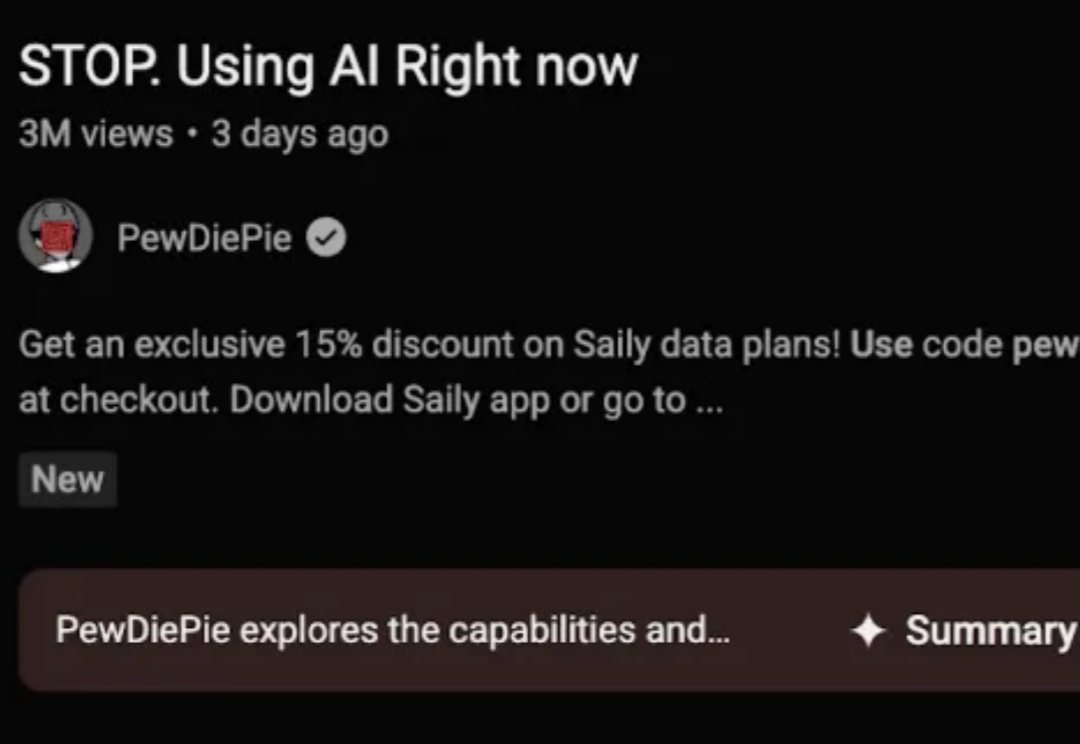
11 月 3 日,全球知名游戏博主 PewDiePie 发布视频,展示其自建本地 AI 系统的全过程。该视频目前浏览量已经超过 300 万,视频标题则赫然写着双关梗 “STOP: Using AI Right now”。

近日,美国南加州大学教授约书亚·杨(Joshua Yang)团队和合作者成功造出一个功能齐全的人工神经元 1M1T1R,这是一种能像真实脑细胞一样工作的人工神经元,有望催生出类似人脑的基于硬件的学习系统,并有望将 AI 转变为更加接近自然智能的形态。
最开始,我们 CTO 计划选择 Coze,但查了下,Coze 整个项目还是比较大,而且后端是 Golang 编写的。我考虑了下,估计后续维护和开发对于中小团队来说比较吃力。各种权衡之后,我们选择了科大讯飞的 Astron Agent。主要原因有两个:
DeepSeek-OCR这段时间非常火,但官方开源的文件是“按 NVIDIA/CUDA 习惯写的 Linux 版推理脚本+模型权重”,而不是“跨设备跨后端”的通吃实现,因此无法直接在苹果设备上运行,对于Mac用户来说,在许多新模型诞生的第一时间,往往只能望“模”兴叹。