“AI产品墓地”里又添了几座新“坟”
“AI产品墓地”里又添了几座新“坟”告诉AI,你即将停运,AI会留下什么样的遗书?
来自主题: AI资讯
8585 点击 2025-06-15 13:25
 搜索
搜索
告诉AI,你即将停运,AI会留下什么样的遗书?

Mercor 所处的赛道是 AI 中一个关键且尚未被充分满足的供需交叉点:下一代 AI 模型对高质量、垂直领域专家级 Human Data 的需求,以及相关人才稀缺所带来的供需不平衡。合成数据无法完全替代 Human Data,尤其是在特定领域知识和复杂判断方面。AI 模型的突破性进展高度依赖于垂直领域专家的“人类智能输入”。

近段时间,关于 AI 自我演进/进化这一话题的研究和讨论开始变得愈渐密集。
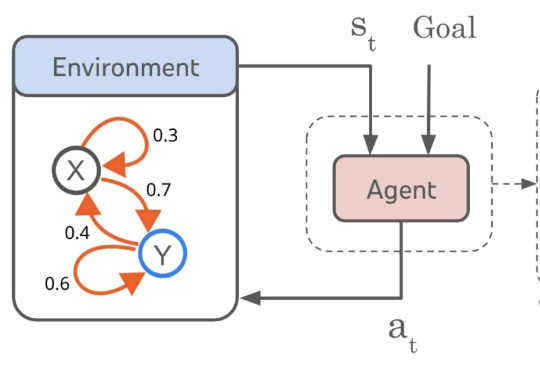
越通用,就越World Models。 我们知道,大模型技术爆发的原点可能在谷歌一篇名为《Attention is All You Need》的论文上。

Landbase 践行着Daniel Saks (萨克斯)称之为"氛围感市场进入"的策略,利用 AI 实现营销触达自动化。本周该公司宣布完成 3000 万美元 A 轮融资,由 Sound Ventures 与现有投资者 Picus Capital 共同领投,8VC、A*和 Firstminute Capital 等既有投资方跟投。

Transformer已满8岁,革命性论文《Attention Is All You Need》被引超18万次,掀起生成式AI革命。Transformer催生了ChatGPT、Gemini、Claude等诸多前沿产品。更重要的是,它让人类真正跨入了生成式AI时代。

今天,一个坐标北京海淀,一支年轻的创业团队,正在小范围 Alpha 测试一款叫 Teamo 的全新 Agent 产品。 给你们看下这个产品的恐怖数据——平均每 2.5 个看到这个产品的人,里面就有 1 个人想要参与 Alpha 内测...
西班牙初创公司 Multiverse Computing 于 6 月 12 日宣布 ,凭借其名为"CompactifAI"的技术优势,已完成 1.89 亿欧元(约合 2.15 亿美元)的巨额 B 轮融资。本轮B 轮融资由 Bullhound Capital 领投,该机构曾投资过 Spotify、Revolut、Delivery Hero、Avito 和 Discord 等企业

据 The Information 报道,有消息称 Meta 将以 148 亿美元收购 Scale AI 49% 的股权,而作为交易的一部分,Scale AI CEO Alexandr Wang 将在 Meta 内部担任高级职位,领导一个新的「超级智能(Superintelligence)」实验室。

「市象」获悉,段楠已在其GitHub主页悄然更新履历:现任京东探索研究院视觉与多模态实验室负责人,带领研究团队研发视觉和多模态基础模型。此前,他曾任阶跃星辰Technical Fellow(2024-2025)和微软亚洲研究院自然语言计算团队资深首席研究员和研究经理(2012-2024)。