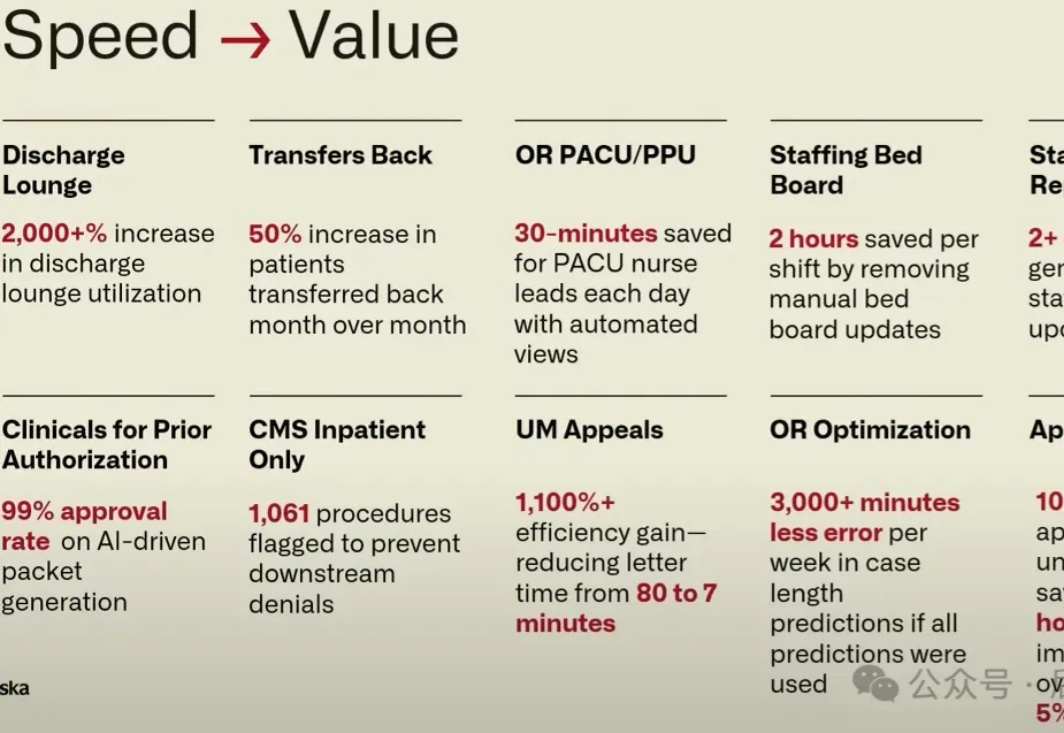
Palantir公布医疗Agent新用例,不止于next level|AIPCon7
Palantir公布医疗Agent新用例,不止于next level|AIPCon76月举办的AIPCon7,又有7家Palantir的客户详细介绍并演示了Agent用例,这次有3家医疗,2家金融,1家电商,1家汽车客户。
来自主题: AI资讯
9755 点击 2025-06-12 16:49
 搜索
搜索
6月举办的AIPCon7,又有7家Palantir的客户详细介绍并演示了Agent用例,这次有3家医疗,2家金融,1家电商,1家汽车客户。

从 Airbnb 到 Figma,从 Ethereum 到 Scale AI,Thiel Fellowship 一直是“小天才”创业者的“秘密起点”之一。Thiel Fellowship 由 PayPal 创始人 Peter Thiel 2011 年创办,每年为每一位入选者提供 10 万美金奖金和“辍学自由”。

作者介绍: 本文作者来自通义实验室 RAG 团队,致力于面向下一代 RAG 技术进行基础研究。该团队 WebWalker 工作近期也被 ACL 2025 main conference 录用。

第一财经「新皮层」独家获悉,MiniMax即将推出文本推理模型,并将开源。半个月前,MiniMax刚刚发布和开源了视觉推理模型Orsta(One RL to See Them All)。MiniMax今年3月做出产品线调整,将旗下现有产品「海螺AI」更名为「MiniMax」,与公司同名,聚焦文本理解和生成;

活久见,OpenAI和谷歌「世纪握手」,达成合作了!另一边的微软,似乎转头就被抛弃了。另外,小扎也受了刺激,下决心亲自组队50人 ,破釜沉舟斥资150亿收购Scale AI,誓要做出AGI。硅谷变天了。

强推理终于要卷速度了。 大模型强推理赛道,又迎来一位重量级玩家。
当OpenAI以65亿美元估值收购前苹果传奇设计师乔纳森·伊夫(Jony Ive)的AI硬件初创公司io时,AI行业对大模型公司的生态战略产生了热议。

2025年5月,美国数字健康企业 Akido Labs 宣布完成6000万美元B轮融资,由 McKesson Ventures 和 Polaris Partners 联合领投,老股东 Andreessen Horowitz(a16z)与 SVB Capital 跟投。融资所得将主要用于扩大其核心平台 ScopeAI 的部署,尤其是在医疗资源匮乏的社区加速落地。

Benchmark 合伙人 Eric Vishria 最近跟 Banana Capital 合伙人 Turner Novak 在其播客 The Peel 做了一个非常精彩的对话,这是我最近觉得非常不错的一个访谈。
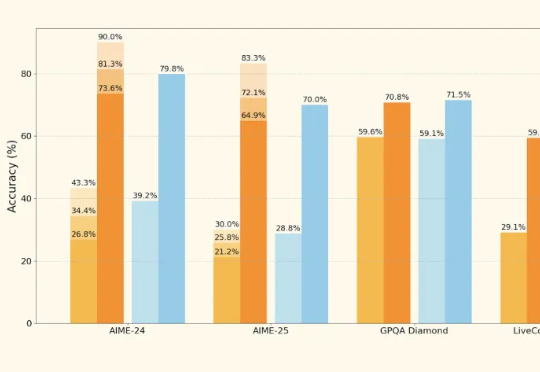
“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。 然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?