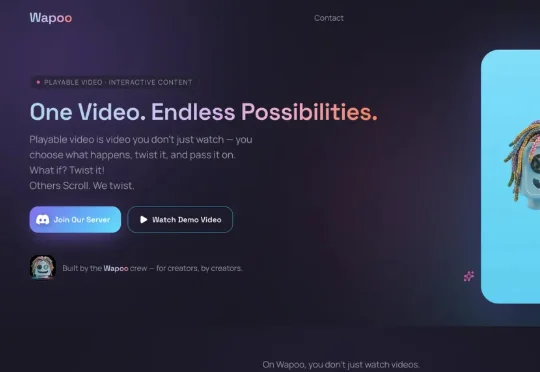
前 TikTok 产品经理创业,AI 视频共创平台 Wapoo 获千万美元天使融资
前 TikTok 产品经理创业,AI 视频共创平台 Wapoo 获千万美元天使融资面向 Gen Alpha 的视频共创社交平台 Wapoo 已完成近千万美元天使轮融资。本轮融资由某互联网集团旗下战略投资方投资,其在全球化产品运营、年轻用户生态及新兴市场拓展方面已具备一定积累,探奇资本担任公司独家融资顾问。目前,Wapoo 团队约 10 人,并已开始筹备下一轮融资。
来自主题: AI资讯
9216 点击 2026-07-30 00:51