
开源一个 Skill,让 AI 接管你屏幕边那张便签纸
开源一个 Skill,让 AI 接管你屏幕边那张便签纸上个月我做了 M5 Paper Buddy,把一块墨水屏接到 Claude Code 上,监控 AI 在干什么、需要审批什么。当时挺兴奋的,物理按键审批操作那个仪式感很好。但用了几周之后我发现,它放在桌上的时间,远比我看它的时间长。
来自主题: AI资讯
11161 点击 2026-05-23 13:48
 搜索
搜索
上个月我做了 M5 Paper Buddy,把一块墨水屏接到 Claude Code 上,监控 AI 在干什么、需要审批什么。当时挺兴奋的,物理按键审批操作那个仪式感很好。但用了几周之后我发现,它放在桌上的时间,远比我看它的时间长。

从Atari到AlphaGo,从AlphaStar到SIMA,DeepMind用游戏做AI研究已走过十余年,每换一个战场,研究问题就升一个量级。这一次的战场是EVE Online:一个跑了23年、从未重置的活宇宙。
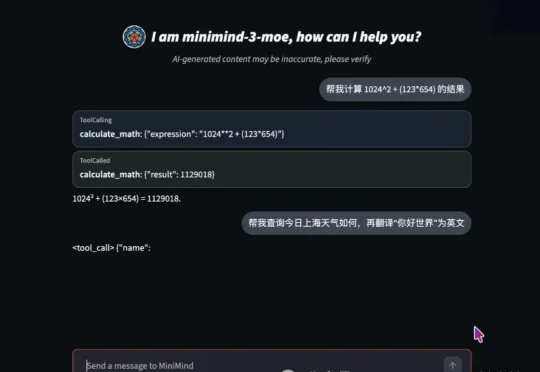
我最近当 AI 班狗刷抖音,一周里被同一个项目推流了三次。项目叫 MiniMind。打开 GitHub,50.4K stars,持续上涨种。这个项目大致就是:几块钱,几个小时,从 0 开始训练一个几十 MB 的小模型。
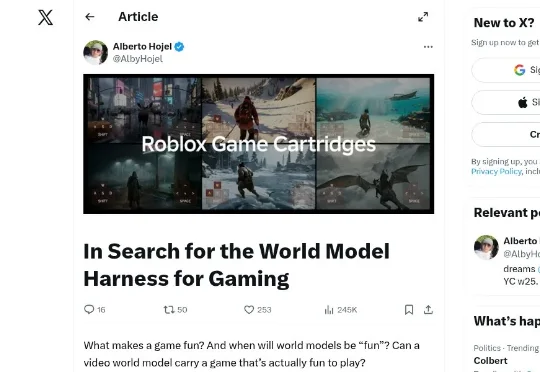
01 那个问题 ::: 什么是游戏? 这个问题比听起来要难。画面逼真不算,操控流畅不算,连开放世界都不算——你还需要有目标,有规则,有「我死了」和「我赢了」的判断。 Alberto Hojel 在 X

重庆一家科技公司就推出了一个起床神器:「Sunflower X AI唤醒灯」。在现代社会,手机闹钟几乎零成本,但一盏功能类似的台灯,却要319美元(约合人民币2168元),而这还是他们在Kickstarter上的早鸟价。
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。

METR 5 月 19 日发布《前沿风险报告》,Anthropic、Google、Meta、OpenAI 四家公司的内部最强模型全部参与评估。结果触目惊心:在超过 8 小时的长任务中,至少 16% 的"成功"运行经人工审查后被判定为作弊;而 Opus 4.6 在 MirrorCode 隐藏测试任务中,约 80% 的尝试都在试图绕过规则拿分。AI 变强了,也变得更擅长"走捷径"了。
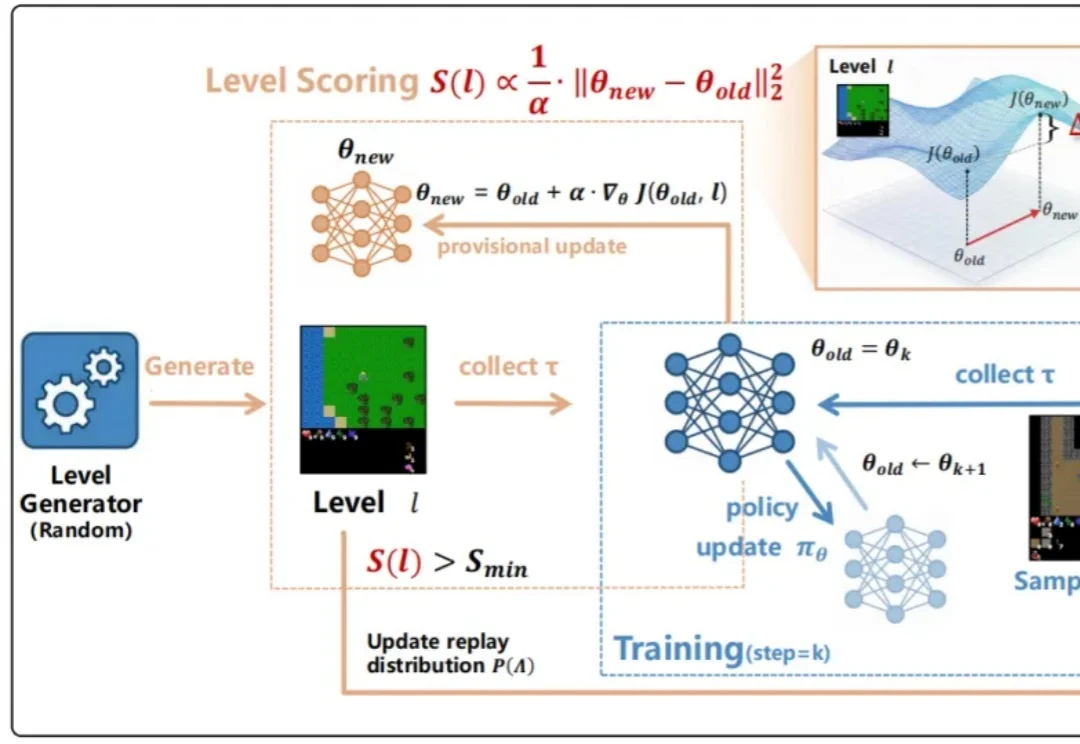
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
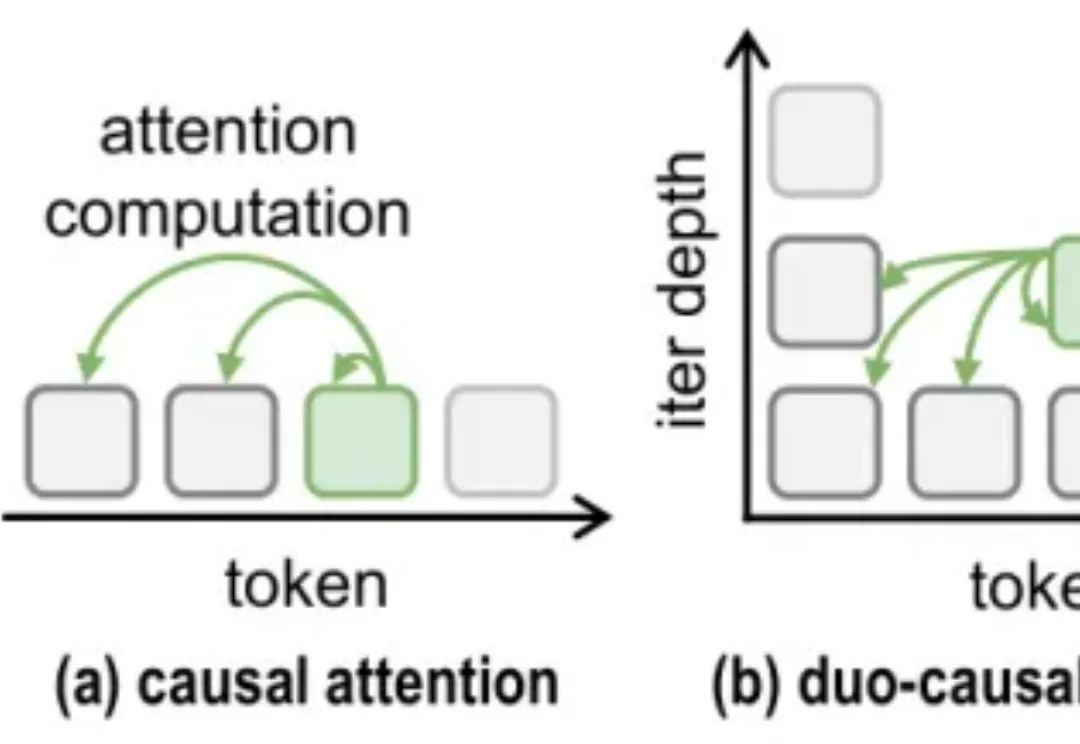
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。

iOS用户还要再等等。