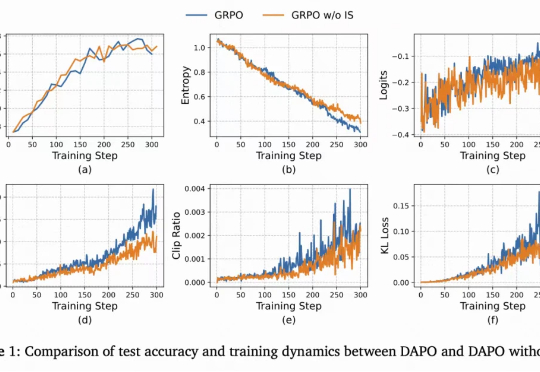
「重要性采样」并不「重要」?快手清华ASPO攻克重要性采样权重错配
「重要性采样」并不「重要」?快手清华ASPO攻克重要性采样权重错配从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。
来自主题: AI技术研报
8618 点击 2025-10-18 11:41
 搜索
搜索
从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。
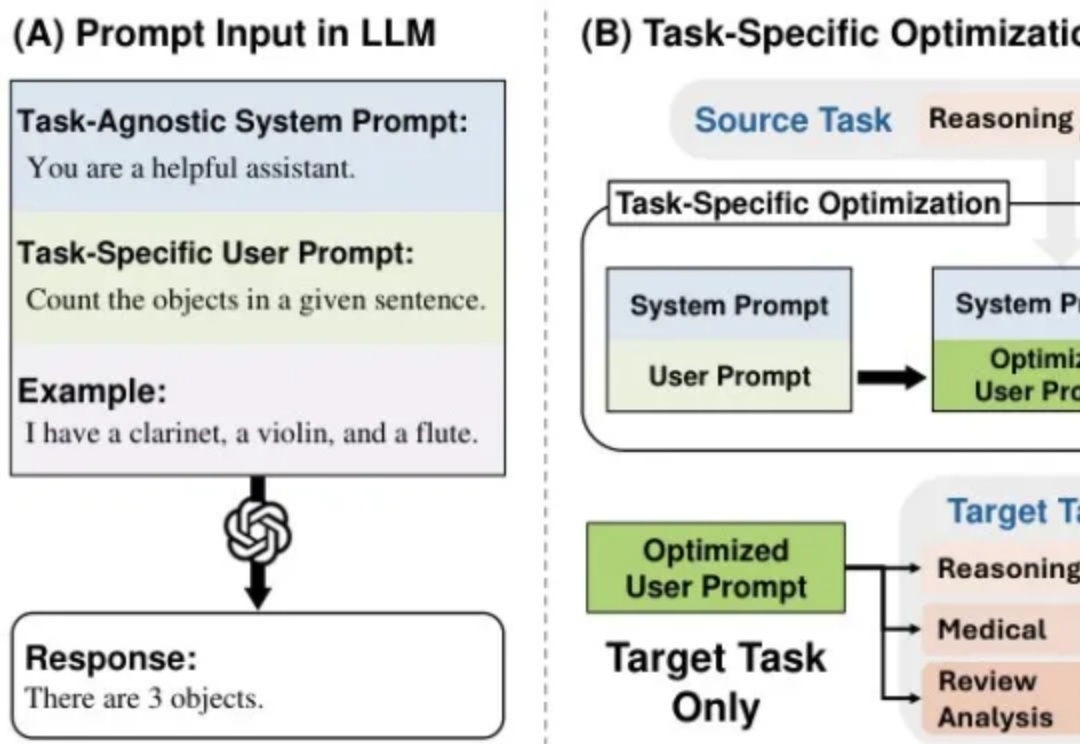
每次更换语言模型就要重新优化提示词?资源浪费且效率低下!本文介绍MetaSPO框架,首个专注模型迁移系统提示优化的元学习方法,让一次优化的提示可跨模型通用。我在儿童教育场景的实验验证了效果:框架自动生成了五种不同教育范式的系统提示,最优的"苏格拉底式"提示成功由DeepSeek-V3迁移到通义千问模型,评分从0.3920提升至0.4362。