
挑战扩散自回归统治!字节提出视觉生成第三种路线,让模型像人类一样边画边改
挑战扩散自回归统治!字节提出视觉生成第三种路线,让模型像人类一样边画边改ber!这个五一假期,我也是真够忙的: 自拍、电影、追剧、街头采访、听音乐会,还抽空回老家结了次婚……
来自主题: AI技术研报
9885 点击 2026-05-14 09:31
 搜索
搜索
ber!这个五一假期,我也是真够忙的: 自拍、电影、追剧、街头采访、听音乐会,还抽空回老家结了次婚……

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。
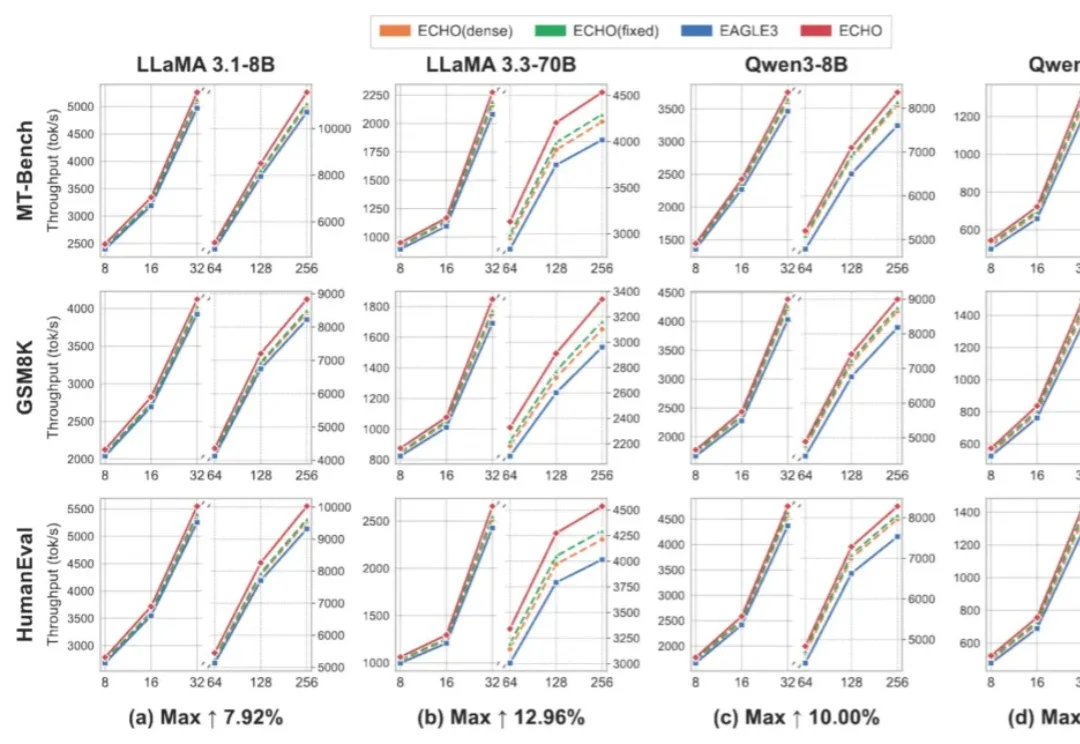
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

在MU Shanghai组织的ClawCon活动上,OpenClaw的社区核心成员自己飞过来,在阿里中心的会议室里,面对着从全国各地赶来的开发者、创业者和用户,和他们一线交流。我们拿到了两个独家对话的机会,受访者是OpenClaw核心维护者Josh,以及OpenClaw Foundation核心成员Vincent Koc。

OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究

近日,字节跳动智能创作部门(Intelligent Creation Lab)提出新作 DreamLite,一个主干网络仅有 0.39B 参数的轻量级统一扩散模型,在单一网络内同时支持文生图(Text-to-Image) 和图像编辑(Text-guided Image Editing)两个任务,是目前已知首个实现这一能力的端侧模型。

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。

Mira Murati 用一年半时间证明了「人机协作」不是一句口号。 5 月 11 日,Thinking Machines Lab 发布了一段研究预览视频,展示了他们所谓的「交互模型」(Interaction Model)。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。

飞拓星驰(FitX AI)宣布完成数百万美金融资,由日初资本领投,光点资本跟投。这笔融资将用于Fit-OS空间智能 Agent 平台的研发,以及首款客厅 AI Native 终端的量产准备——预计 2027 年 CES 全球首发。