
曝OpenAI日亏超5亿,但Anthropic快盈利了
曝OpenAI日亏超5亿,但Anthropic快盈利了据The Information今日报道,两位知情人士透露,OpenAI今年第一季度的营收约为57亿美元(约合人民币387.7亿元),比其主要竞争对手Anthropic同期收入高出近10亿美元(约合人民币68亿元)。
来自主题: AI资讯
8332 点击 2026-05-22 14:20
 搜索
搜索
据The Information今日报道,两位知情人士透露,OpenAI今年第一季度的营收约为57亿美元(约合人民币387.7亿元),比其主要竞争对手Anthropic同期收入高出近10亿美元(约合人民币68亿元)。

AI办公彻底变天了!阿里QoderWork重磅发布全球首个AI Native自定义工作台,推出设计、PPT、写作三大领域模式。AI办公正式从「对话驱动」走向「领域驱动」。
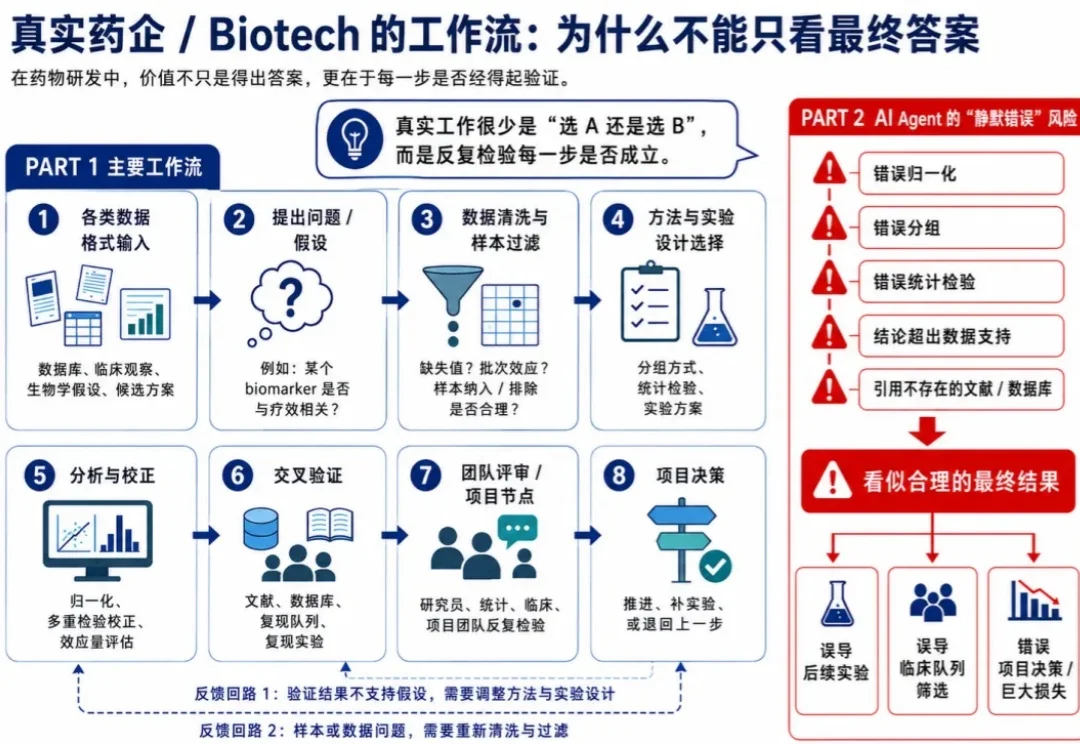
xbench,就是红杉自己弄的那个中立评测lab,刚刚又整了个新活:让 AI 做药企的数据分析,跟人类实习生比个高低,然后遥遥领先的赢了
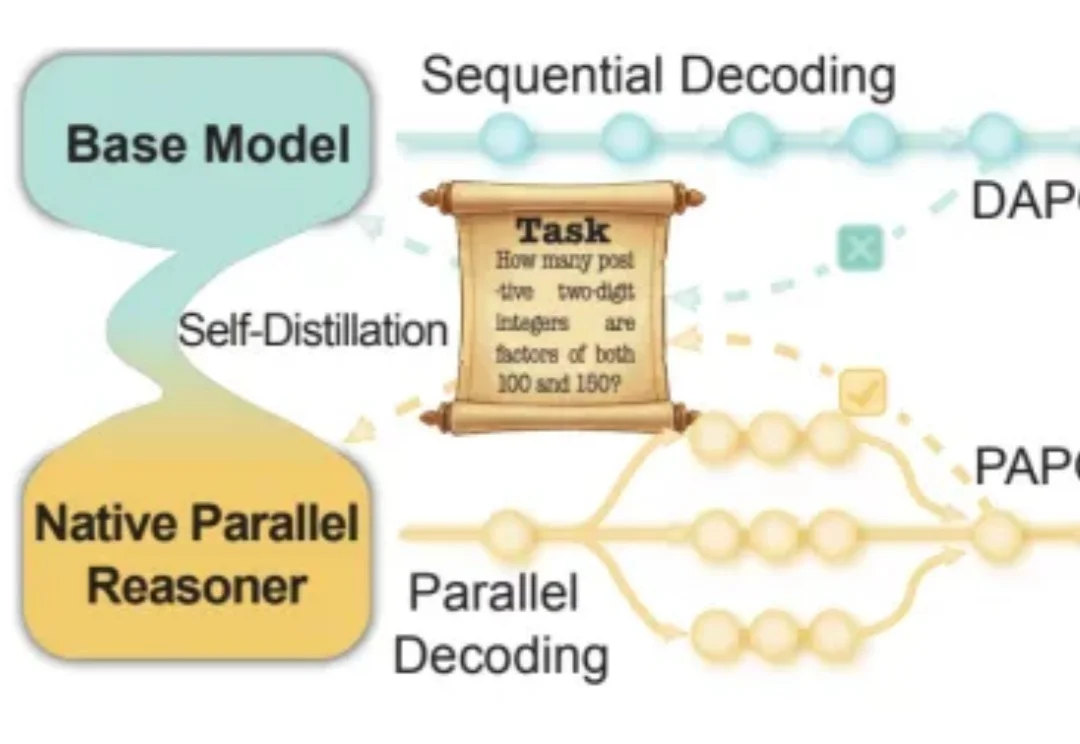
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。
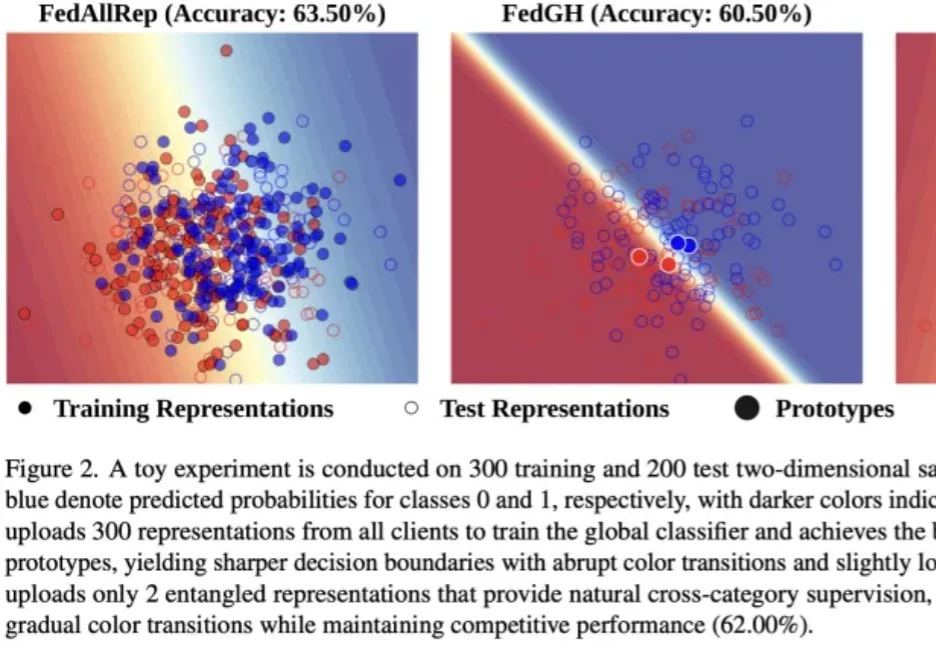
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。
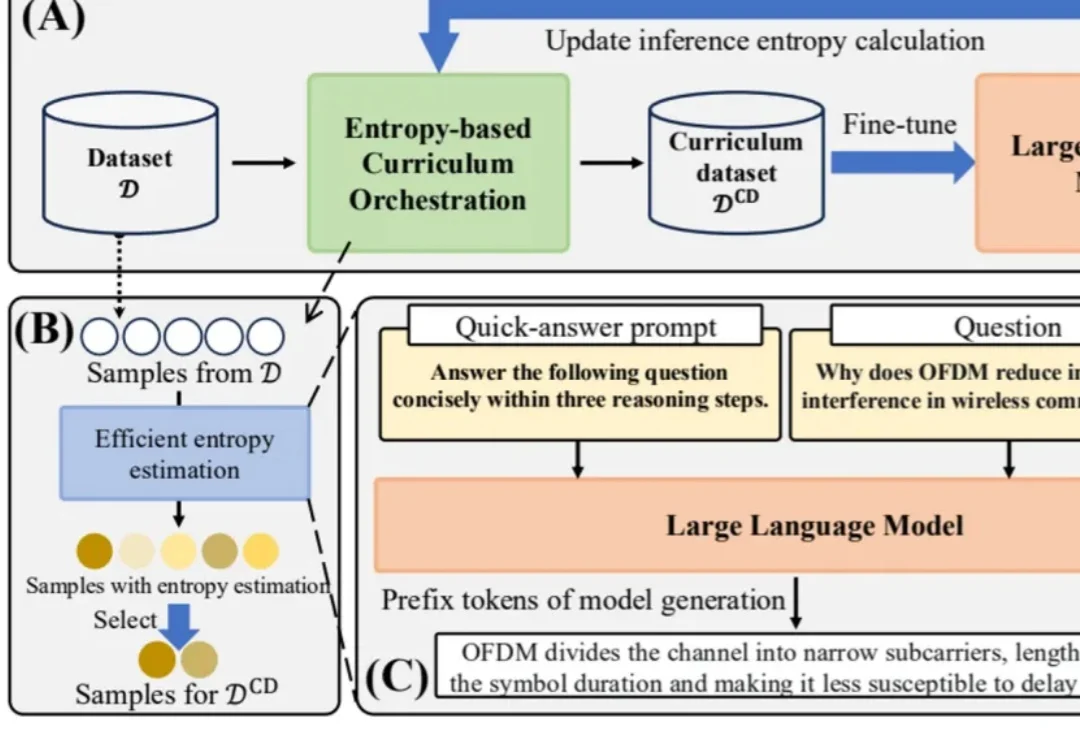
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
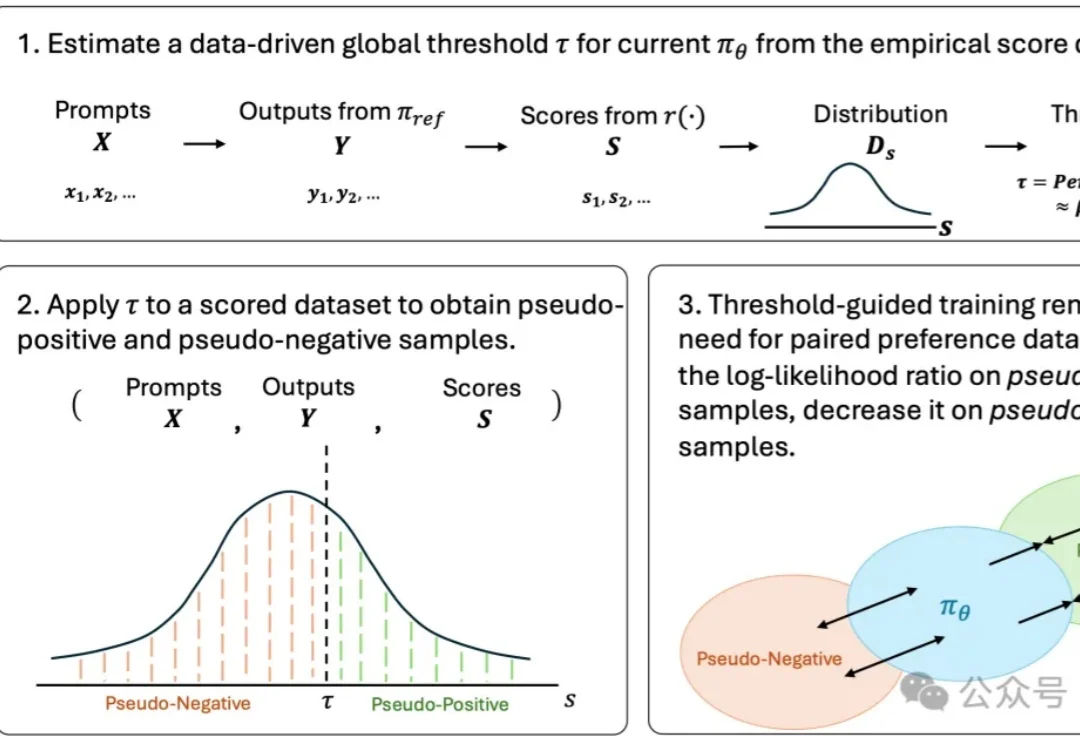
生成模型的偏好对齐,可能正在进入一个新的阶段。

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,

Anthropic 刚刚出了一份 36 页的创始人手册:创建一家 AI Native 的公司,几个人,做几百人的事儿。由着这个问题,手册把创业拆成四个阶段(想法、MVP、上线、规模化),每个阶段讲清楚该做什么、容易踩什么坑、Claude 的三个产品形态(Chat、Cowork、Code)分别在什么时候用

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。