从LLM到JEPA,中国团队正在把“世界模型”搬进细胞内部
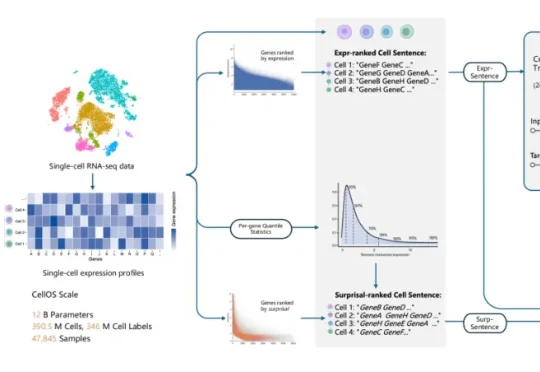
从LLM到JEPA,中国团队正在把“世界模型”搬进细胞内部最近,AI虚拟细胞(AIVC)赛道,迎来关键突破!作为全球最早布局该领域的企业之一,百曜科技正式发布全球首个基于LLM-JEPA架构的AI虚拟细胞世界模型——AURA CellOS。
来自主题: AI资讯
9216 点击 2026-07-04 11:18
 搜索
搜索
最近,AI虚拟细胞(AIVC)赛道,迎来关键突破!作为全球最早布局该领域的企业之一,百曜科技正式发布全球首个基于LLM-JEPA架构的AI虚拟细胞世界模型——AURA CellOS。

三年后,这个判断变成了一家叫FrontierX的公司,和它的产品Aura——一个球形的、能在室内自由移动、端侧部署感知和模型的「开放定义的机器人」。FrontierX诞生于杭州,是一家以感知智能为核心的AI原生硬件公司,由来自浙江大学和阿里巴巴的团队创立。团队背景多元,涵盖硬件工程师、算法工程师、产品经理和工业设计师。
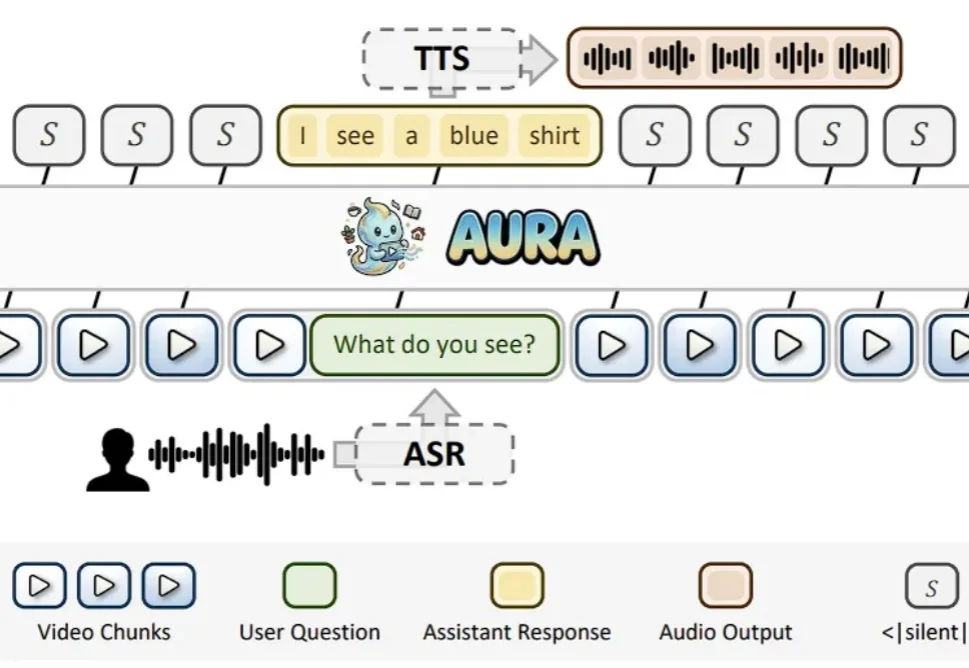
近年来,视频多模态大模型(VideoLLM)发展迅猛,在视频描述、视频问答、时序定位等任务上不断刷新性能上限。随着模型能力持续增强,业界也开始思考一个更重要的问题:视频大模型能不能不再只是 “看完一段视频再回答”,而是真正进入实时世界,持续观察、实时理解,并在关键时刻主动给出反馈?

华尔街知名机构Needham的分析师Laura Martin并不这么看,而其主要的担心,集中在人工智能(AI)上。其曾在研报中指出:随着人工智能的发展,苹果公司的霸主地位最终可能会被颠覆。