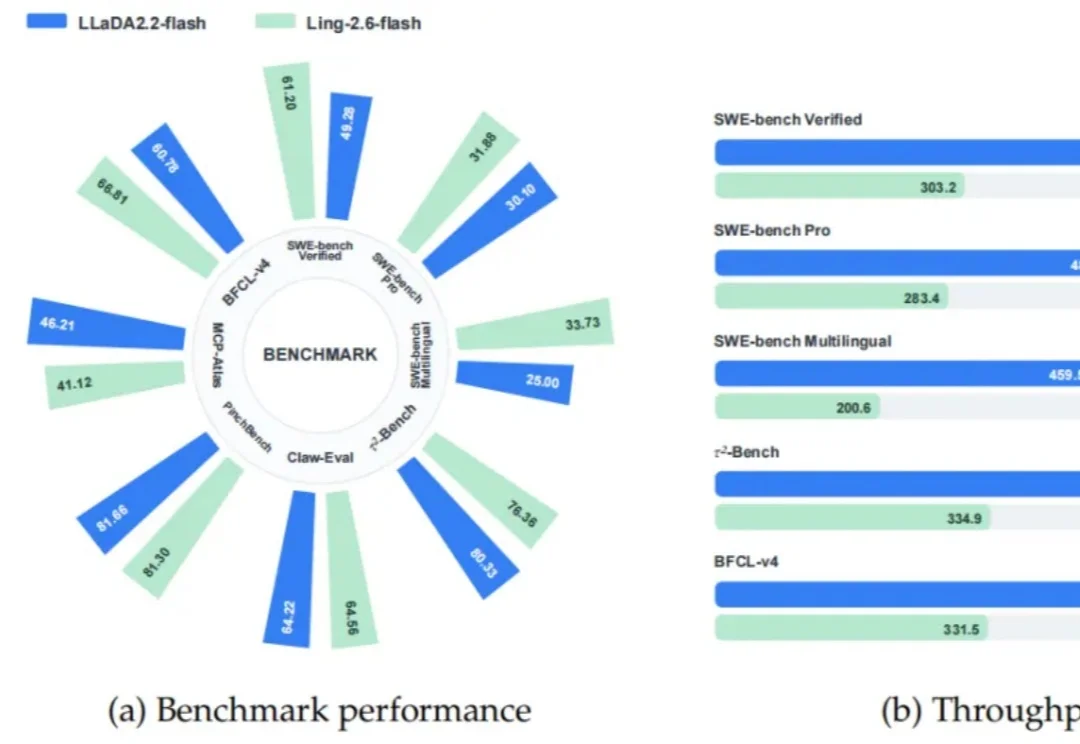
全球首个Agentic扩散模型来了:边行动边纠错,128K上下文追平自回归
全球首个Agentic扩散模型来了:边行动边纠错,128K上下文追平自回归终于!Agent赛道,不再是自回归(AR)模型一家独大。
来自主题: AI技术研报
8807 点击 2026-07-29 10:10
 搜索
搜索
终于!Agent赛道,不再是自回归(AR)模型一家独大。
哈喽,大家好,我是刘小排。 刚才,有关注我 Token 消耗的小伙伴已经发现:我今天的 Codex 消耗突然很低。
7月23日,吴恩达在GitHub上发布了一个叫OpenWorker的开源工具。7天,9.7k个Star。

微软周一发布了一款名为Project Perception的新AI安全产品,该产品由微软自主研发、专门针对网络安全任务打造的新一代AI模型驱动。微软将这款产品定位为Anthropic旗下Mythos模型的低成本替代方案,后者同样利用AI模型自动发现软件漏洞。

在WAIC 2026上,专注于通用具身智能人形机器人研发的「青心意创」出乎意料地带来了一款具身角色智能机器人「Amoo」。

7月27日,美团正式上线了CatPaw,一个全场景AI Agent平台。准确说,是「内部练了三年,现在放出来给所有人用」。

2026 年 2 月,潘志刚(David Z. Pan)向 DeepTech 透露,他正在将一套 AI 电路推理方法扩展到版图设计,但“细节暂不便公开”。5 个月后,这位德州大学奥斯汀分校教授宣布担任 DeepWeave 联合创始人兼 CTO。

一个Agent可以完整读过任务要求,亲手执行过失败命令,也能在十分钟前准确定位错误根因,但到了下一轮决策,它仍可能像第一次遇到问题一样重走旧路:再次写入已经确认不可写的目录,重新尝试已经被证伪的参数,或者修好局部测试后忘掉最初的验收条件。

给图像生成模型一张人物参考图,它大概率能抓住身份特征。
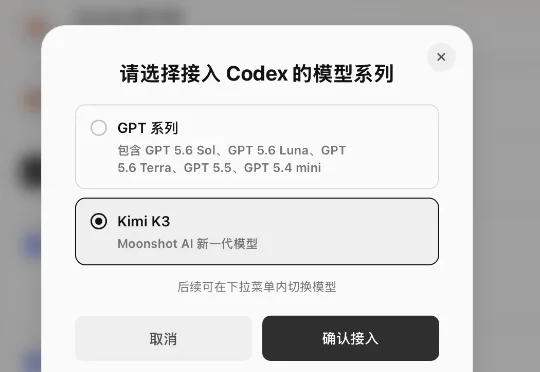
尽管Codex官方是支持第三方模型接入的,但是Codex 走的是 Responses API,而 K3 给的是 OpenAI 兼容的 Chat Completions API,两套协议对不上。所以Kimi 官方给的方案就是本地挂上CC Switch 或 codeproxy 这类第三方的转换器。