
北大伯克利联手“拷问”大模型:最强Agent也才40分!新基准专治“不听话”的AI分析师
北大伯克利联手“拷问”大模型:最强Agent也才40分!新基准专治“不听话”的AI分析师给大模型当老师,让它一步步按你的想法做数据分析,有多难?
来自主题: AI技术研报
8842 点击 2025-06-10 16:25
 搜索
搜索
给大模型当老师,让它一步步按你的想法做数据分析,有多难?

刚刚,全新AI基准测试工具xbench诞生,通过双轨评估体系和长青评估机制,追踪模型能力与实际场景价值。

随着基础模型的快速发展和 AI Agent 进入规模化应用阶段,被广泛使用的基准测试(Benchmark)却面临一个日益尖锐的问题:想要真实地反映 AI 的客观能力正变得越来越困难。
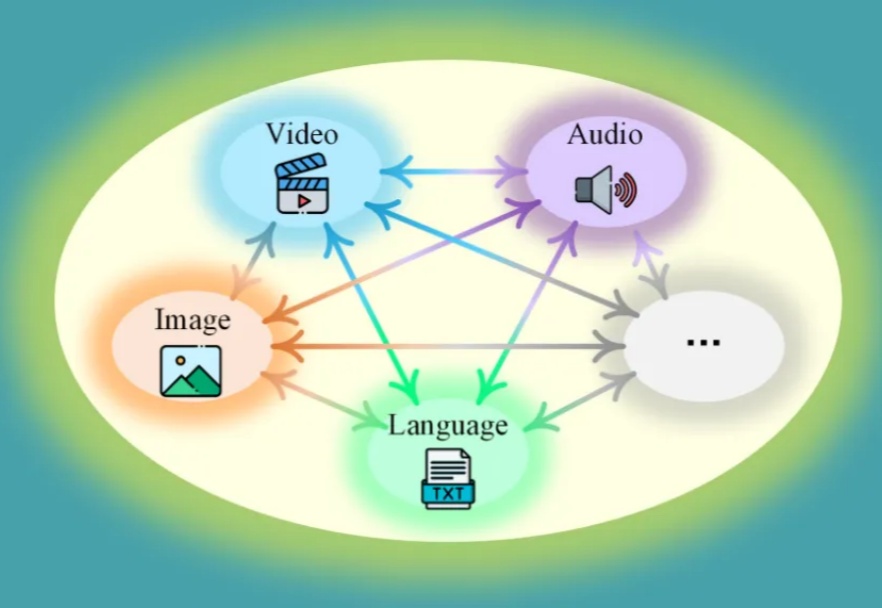
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
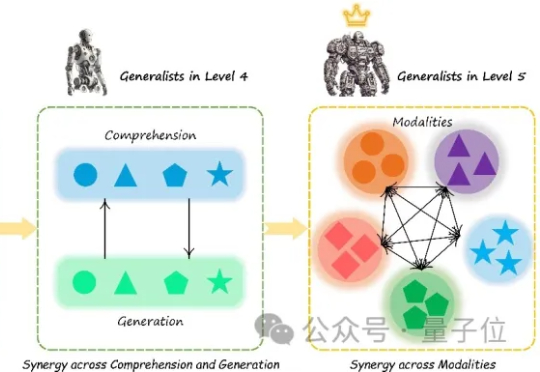
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。
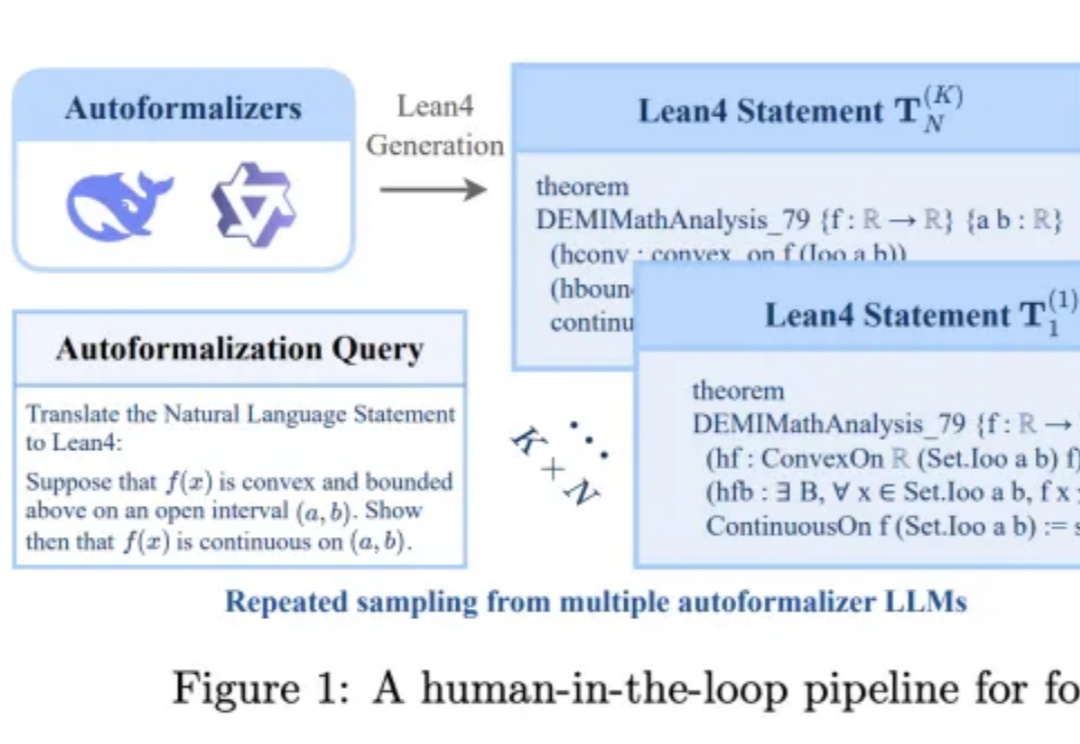
最强AI模型面对5560道数学难题,成功率仅16.46%?背后真相大揭秘。

近来风头正盛的GPT-4.5,不仅在日常问答中展现出惊人的上下文连贯性,在设计、咨询等需要高度创造力的任务中也大放异彩。
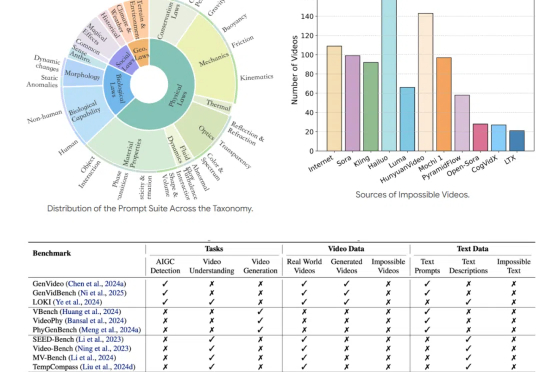
随着人工智能合成视频(AIGC)技术的飞速发展,我们正步入一个由 AI 主导的视频创作时代。

刚刚开源的新基准测试PaperBench,6款前沿大模型驱动智能体PK复现AI顶会论文,新版Claude-3.5-Sonnet显著超越o1/r1排名第一。与去年10月OpenAI考验Agent机器学习代码工程能力MLE-Bnch相比,PaperBench更考验综合能力,不再是只执行单一任务。