
机器人需要一个「思考系统」:τ0-VLA让具身智能迈向长程任务时代
机器人需要一个「思考系统」:τ0-VLA让具身智能迈向长程任务时代2026 WAIC 刚刚落幕,具身智能无疑是最受关注的技术方向之一。
来自主题: AI技术研报
5691 点击 2026-07-27 16:09
 搜索
搜索
2026 WAIC 刚刚落幕,具身智能无疑是最受关注的技术方向之一。

Z Potentials 获悉,AI多模态内容互动娱乐社区海艺近期完成超亿元人民币B轮融资,由视觉中国、华盖创赢、祥峰投资联合领投,广发信德、天投资本、川创投、广州合伟永晟参与。

脑机接口从意念控制光标走向更大范围的大脑读写。

刚读了一篇 AI4AI 论文《AI4AI at Scale》,来自 XYZ Agentic Team。还是第一次听到这个 Lab。他们用 AI4AI 的方式做出了两个很强的搜索 agent,也公开了方法。借这篇 paper 讲讲 AI4AI 到底怎么工作,下面尽量少堆术语。

现在的 Agent 将所有的工程线索和垃圾噪音都一股脑扔进 Chat Context 里,缺乏一层独立、结构化的 Engineering State 来做隔离与控制。为了打破这个瓶颈,Valkor 联合浙江大学智能计算与软件研究中心、伦敦大学学院(UCL)软件工程团队正式推出并开源了 loom。

“包括Physical Intelligence在内,如今的北美头部具身智能公司离成熟都还有不短的距离。整个领域,也还没出现真正的奠基性工作。”“中国真正领先的,恰恰是机器人硬件。美国同样没有成熟答案,中国公司又何必急着把自己称为‘中国版XX’?”

近日,Z Potentials 获悉,AI4Bio“模型 × 本体”公司 Fullive.ai 正式宣布完成种子++轮融资。至此,公司在 4 个月内已连续完成三轮融资。本轮资金将主要用于首款 AI 睡眠硬件 Somni 的研发与量产推进、AI4Bio 前沿技术储备,以及 Fullive.ai 在“模型 × 本体”方向上的技术体系建设。

2023 年他在深圳创立听象科技,推出自有品牌昂听 ELEHEAR(下文统一简称 ELEHEAR)。前期发布 Alpha 系列产品试水助听器市场,2024 年 10 月推出旗舰产品 Beyond,凭借全栈自研的 AI 助听器+远程实时验配的新模式,用 1 年时间做到了美国亚马逊助听器类目 Top1,年销超 1500 万美元,市场份额从 1% 迅速增长至 18%。

近日,Meta 首席 AI 官、被称为公司“最高薪员工”的 Alexandr Wang,因一句简单却极具挑衅意味的话引起热议:“gemini who?(Gemini,谁啊?)”这场口水战的背后,其实是一场 AI 巨头之间的公开较量——Meta 最新模型 Muse Spark 1.1 在一份模型排行榜中超过了谷歌刚发布的 Gemini 3.6 Flash
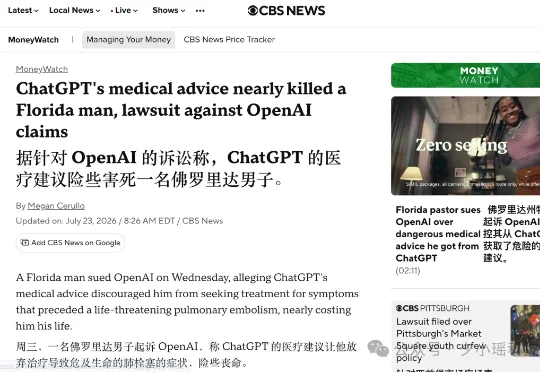
7月22日,美国佛罗里达州的牧师 Scott Winters,在旧金山把 OpenAI 和它的 CEO Sam Altman 告了。Winters 称自己在 2025 年夏天身体开始不对劲,症状持续有六个星期,这期间他没往医院跑,而是一遍遍去问 ChatGPT-4o 。可他后来才知道,那些被他反复描述的症状,其实是肺栓塞的征兆。血块堵在肺部血管里,随时会要命。