
刚刚,Ilya官宣出任SSI CEO!送走「叛徒」联创,豪言不缺GPU
刚刚,Ilya官宣出任SSI CEO!送走「叛徒」联创,豪言不缺GPU就在刚刚,Ilya出现了!他大义凛然发文,自封为SSI唯一CEO,而Daniel Levy将担任总裁。要实现SSI的梦想,多少钱都不卖。
来自主题: AI资讯
9390 点击 2025-07-04 08:59
 搜索
搜索
就在刚刚,Ilya出现了!他大义凛然发文,自封为SSI唯一CEO,而Daniel Levy将担任总裁。要实现SSI的梦想,多少钱都不卖。
一次性揭秘Gemini多模态技术!就在刚刚,Gemini模型行为产品负责人Ani Baddepudi在谷歌自家的开发者频道开启了爆料模式。

Landbase 践行着Daniel Saks (萨克斯)称之为"氛围感市场进入"的策略,利用 AI 实现营销触达自动化。本周该公司宣布完成 3000 万美元 A 轮融资,由 Sound Ventures 与现有投资者 Picus Capital 共同领投,8VC、A*和 Firstminute Capital 等既有投资方跟投。

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。
当大多数人还在学习如何使用ChatGPT生成简单文本时,一对年轻创始人已经让AI为你直接构建完整的移动应用。Levan Kvirkvelia和Daniel Dhawan创建的Rork让人想起了硅谷的电影剧情:从信用卡债务缠身、朋友家地板上的床垫,到一条病毒式推文引来百万美元融资,这家初创公司在vibe coding领域掀起了新浪潮。
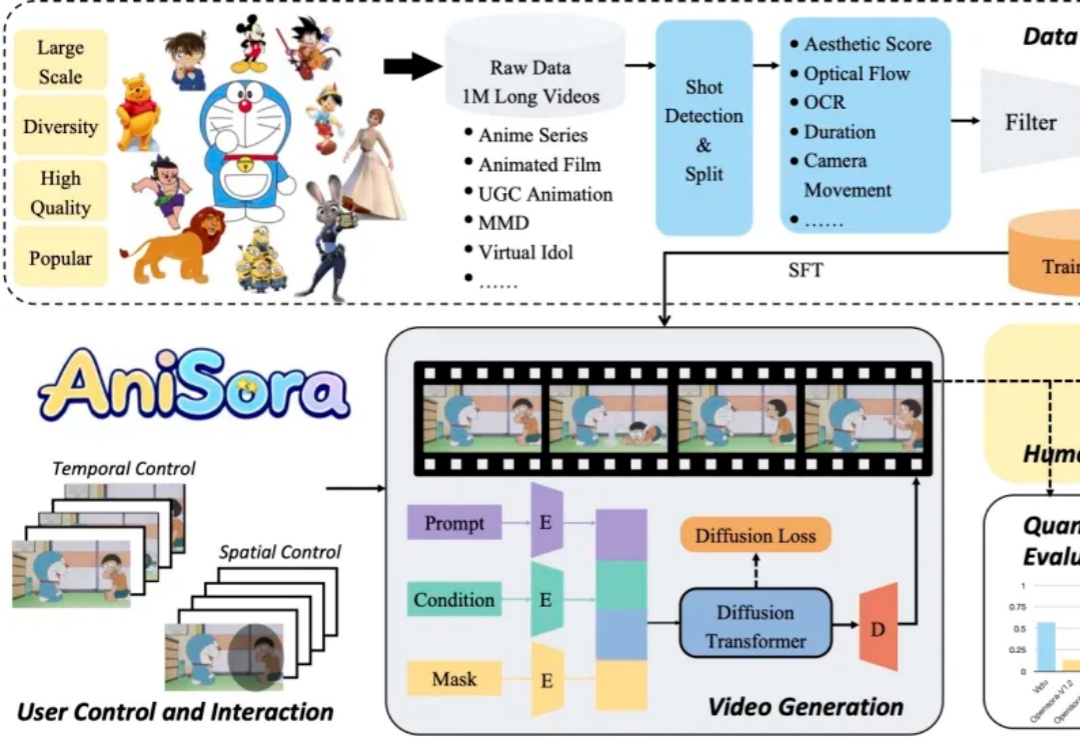
B 站开源动画视频生成模型 Index-AniSora,支持番剧、国创、漫改动画、VTuber、动画 PV、鬼畜动画等多种二次元风格视频镜头一键生成!

ManiSkill-ViTac 2025视触觉融合挑战赛揭榜!全球42支团队激烈交锋,中国团队包揽三金,刷新国际榜单。
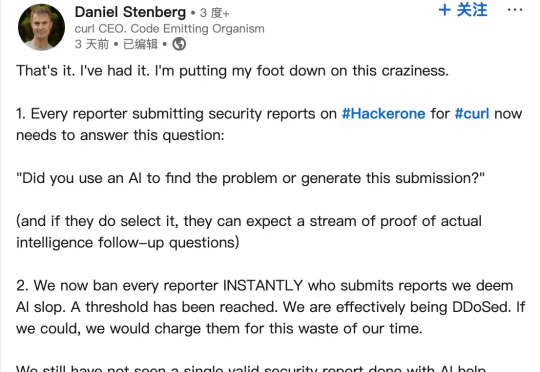
近日,curl 项目(一款用于通过 URL 传输数据的命令行工具和库)创始人 Daniel Stenberg 在领英发帖称,已经受够了由 AI 生成的大量“垃圾”漏洞报告,因此近期引入额外复选框,用以过滤此类平白浪费维护人员时间的低效提交内容。
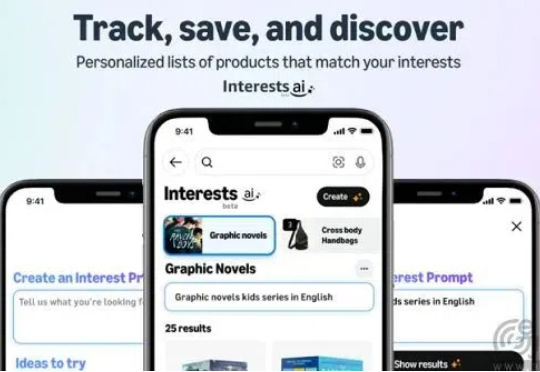
到了2025年,即便是对科技不太感兴趣的人应该也会对人工智能(AI)如雷贯耳了,AI改变生活也早已不是预言,而是正在发生的现实。既然AI是热点,也就意味着必然有人会试图浑水摸鱼,最近就有美国的投资者因此遭殃。近日美国司法部方面透露,AI购物应用Nate的创始人Albert Saniger被指控通过虚假宣传AI技术,骗取了超过4000万美元的投资。
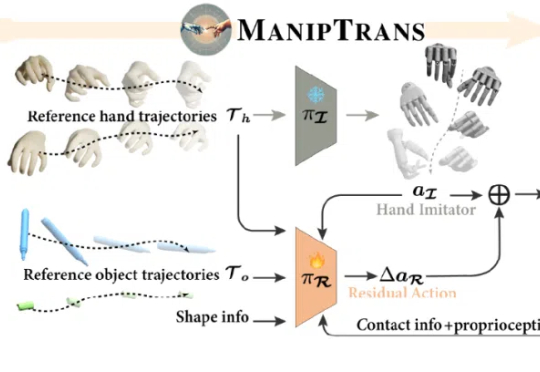
近年来,具身智能领域发展迅猛,使机器人在复杂任务中拥有接近人类水平的双手操作能力,不仅具有重要的研究与应用价值,也是迈向通用人工智能的关键一步。