我 Skill 化了耿同学的「学术打假方法论」,致敬
我 Skill 化了耿同学的「学术打假方法论」,致敬我一直全程关注他打假的全过程,也一直有个想法:耿同学做的这些,能不能让 AI 分担一部分?这几天我琢磨了很久,也 Vibe Coding 了很久,最后做出来一个初版的 「学术打假 Skill——research-integrity-auditor」。
来自主题: AI资讯
10245 点击 2026-05-08 11:54
 搜索
搜索
我一直全程关注他打假的全过程,也一直有个想法:耿同学做的这些,能不能让 AI 分担一部分?这几天我琢磨了很久,也 Vibe Coding 了很久,最后做出来一个初版的 「学术打假 Skill——research-integrity-auditor」。
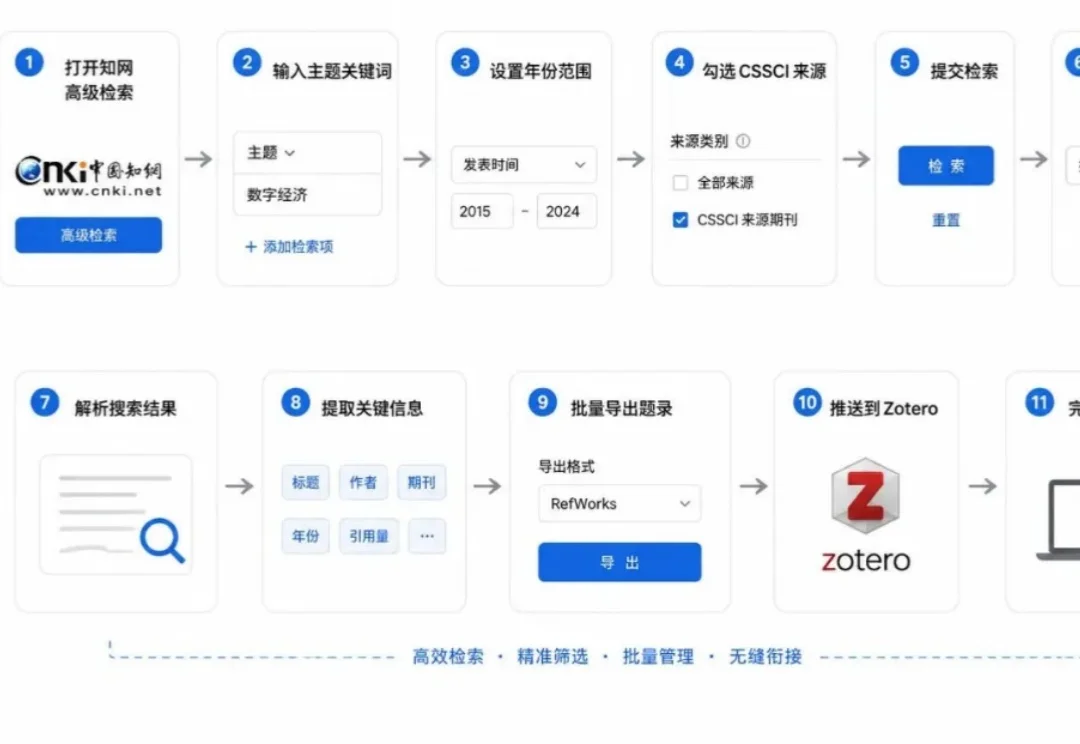
做文献调研时,很多人的流程大概是这样的:

Salesforce CEO Marc Benioff近日甩出一份招聘计划:要一口气招进1000名应届生或实习生,与他们一起搭乘AI快车。IBM更猛,北美入门级岗位直接扩招3倍,麦肯锡、Cognizant紧跟其后。智能体时代,一批10年前根本不存在的「金饭碗」正在批量诞生,应届生这个词,也将被重写。
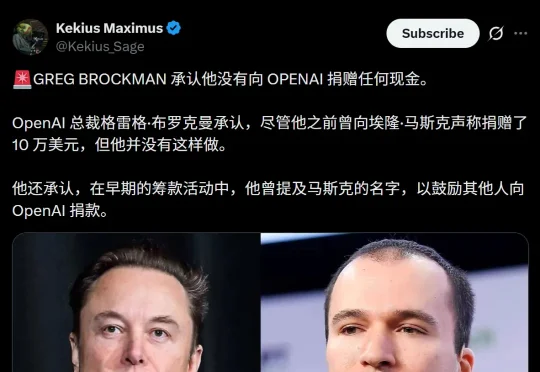
太炸裂了!刚刚,OpenAI总裁Brockman当庭承认:自己投入0美元,持有OpenAI营利部门300亿美元股份(马斯克捐了3800万,得到的是0)。更炸的是,Brockman和奥特曼都悄悄持有Cerebras个人股份。Gary Marcus直言,这是马斯克最接近赢的一次。
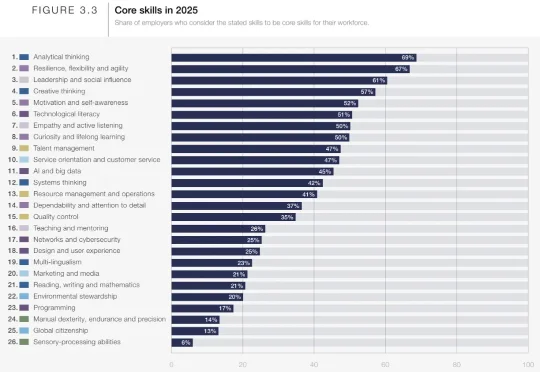
最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
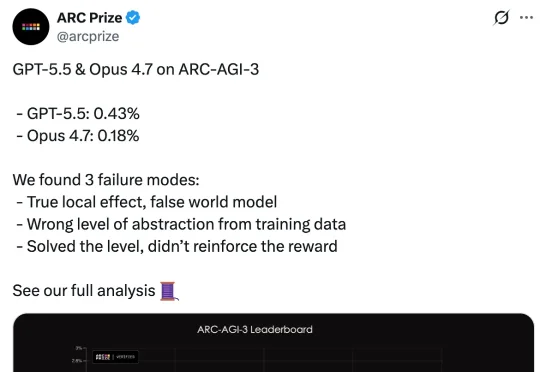
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。

OpenAI刚用Deep Research抢了先手,谷歌直接掀桌!DeepMind祭出研究智能体双杀,Max版质量评分从66.1%暴拉到93.3%,知识工作自动化的军备竞赛正式进入贴身肉搏。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。

2026 年初,浙江大学发表了一篇系统性的 SoK 论文《Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward》,给Skill下了一个正式定义。