
谷歌搜不到的80%互联网,AnySearch全打通了!开发者连夜接入
谷歌搜不到的80%互联网,AnySearch全打通了!开发者连夜接入传统API集成已死!在这个Agent满地跑的时代,被低估的搜索终于迎来了第四次范式转移。AnySearch的问世,让Agent告别了单一的网页总结功能,转而通过获取可信的结构化信息,真正具备触达并连接现实世界的能力。
来自主题: AI技术研报
5813 点击 2026-05-19 10:59
 搜索
搜索
传统API集成已死!在这个Agent满地跑的时代,被低估的搜索终于迎来了第四次范式转移。AnySearch的问世,让Agent告别了单一的网页总结功能,转而通过获取可信的结构化信息,真正具备触达并连接现实世界的能力。
用Claude Code写论文的一整套流水线,有人打包开源出来了。完全戳中了学生党的痛点,github星标直达6.4k。项目名叫academic-research-skills(以下简称ARS),是一套Claude Code技能包。
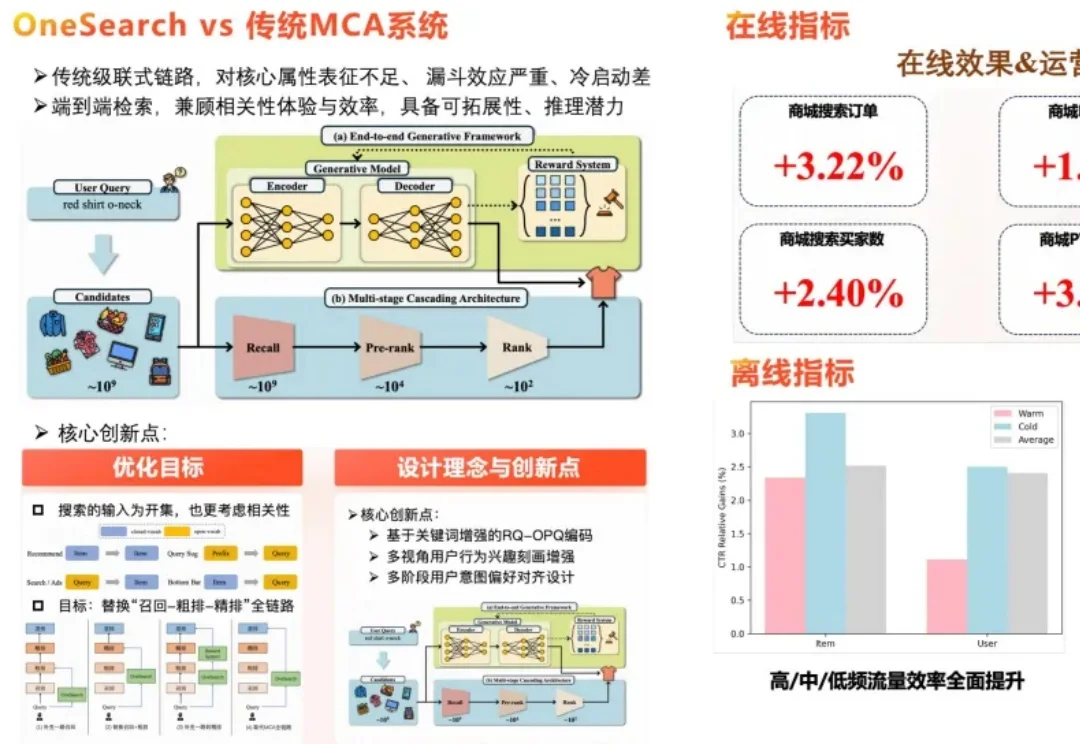
针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。

如果把AI丢进一个没有标准答案的工程现场,它还能活下来吗?

科研,能被 AI 全程加速吗?

2011年,Marc Andreessen写下“软件正在吞噬世界”。2026 年,Fortune用了一句话总结当前局面:“那个吃掉世界的东西,正在被吃掉。 ”

数学界尘封32年的拉姆齐数经典难题被打破!浙大校友王宜平借助自研AI框架ScaleAutoResearch-Ramsey,成功将拉姆齐数R(3,17) 下界从92提升至93,终结了自1994年以来长期停滞的纪录。

最近,研究机构Palisade Research发布了一项令整个行业震惊的成果—— 研究员在终端只输入了4个单词,AI就完成了从黑客攻击到自我繁衍的全过程。这是AI通过黑客手段实现自我复制的首个纪录!
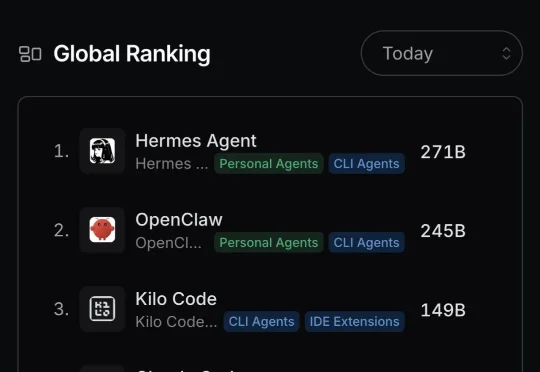
5月9日,Hermes Agent(昵称:爱马仕)登顶OpenRouter全球应用调用量榜首,首次超越OpenClaw(昵称:龙虾)。据OpenRouter应用Token消耗榜最新数据,这一Nous Research旗下开源自进化Agent产品登顶全球应用Token消耗榜,单日Token消耗量达到271B,也就是2710亿Token。
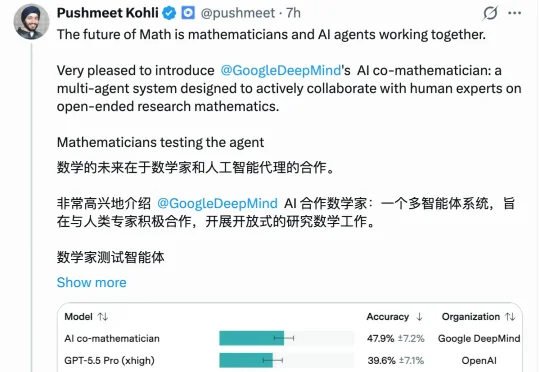
群论领域几十年无解的第21.10号问题,被牛津数学家Marc Lackenby用谷歌一个新系统破解了。过程也很有意思:AI第一次给出的证明是错的,被系统里的审查Agent揪出了漏洞。