
全球最大AI榜单塌房!52%高分答案全是胡扯,硅谷大厂集体造假?
全球最大AI榜单塌房!52%高分答案全是胡扯,硅谷大厂集体造假?谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?最近,2025年底的一篇名为《LMArena is a cancer on AI》的文章被翻了出来。登上了Hacker News的首页,引起轩然大波!
来自主题: AI资讯
9064 点击 2026-01-09 11:35
 搜索
搜索
谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?最近,2025年底的一篇名为《LMArena is a cancer on AI》的文章被翻了出来。登上了Hacker News的首页,引起轩然大波!

一场AI界的《创造101》火了!LMArena让你盲投选出最强AI,三年从校园项目逆袭,刚刚融1.5亿美元,估值飙到17亿美元。众包投票挑战专家权威,争议四起,却已成行业标杆。你的票,就能决定下一个AI顶流!
时间过得太快了,一转眼就来到了 2025 年的年底。我们距离 2026 年只剩下了 8 天。回看 AI 模型和产品突飞猛进这一年,中美两家 AI 阵营的行业发展路径有了挺大的区分,大家的关注度不再是单一模型、单一能力,而是“模型+工程+场景”的复合能力。这个变化在年底愈发明显。

在Alpha Arena 1.5赛季的美股真金白银实盘中,Grok 4.20完胜GPT-5.1和Gemini 3.0 Pro等一众顶流模型,在对手全线亏损的情况下,独自斩获了12.11%的正收益。成功背后的秘密是Grok对X的推文反映的市场情绪的及时精准捕捉。

ChatGPT发布距今已近36个月,面对OpenAI的领先,哈萨比斯带领谷歌AI全面反攻,通过新发布的Gemini 3强势回归。Gemini 3在LM Arena等多个模型榜单登顶,表现优于GPT-5及其他模型,上演了一场完美逆袭。

AI新王来了!马斯克Grok 4.1静默上线,一夜之间登顶LMArena,Gemini 2.5 Pro却被按在地上摩擦。主打情商智商在线,算力又扩增一个数量级。这一次,Grok 4.1一共放出了两大版本:Grok 4.1 Thinking和Grok 4.1。
大模型编程最近太猛了。
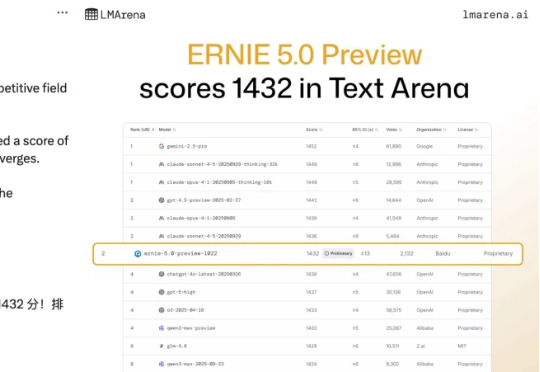
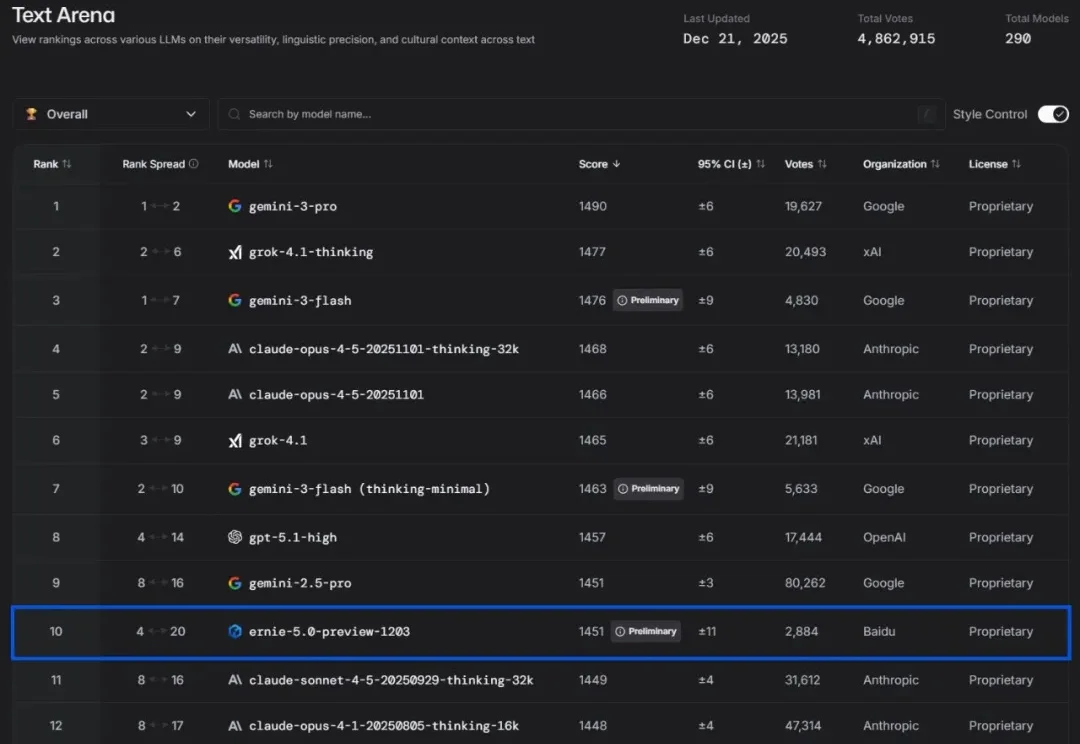
「Baidu is back」,在业界权威大模型公共基准测试平台 LMArena 发布最新一期文本竞技场排名(Text Arena)之后,有人发出了这样的惊呼。根据 11 月 8 日凌晨 LMArena 的最新排名显示,百度文心最新模型 ERNIE-5.0-Preview-1022(文心 5.0 Preview)在文本榜单上一举跃居全球并列第二、国内第一。

「在大模型热潮中,如何真正评测它们的智能?」

当AI模型排行榜开始被各种刷分作弊之后,谁家大模型最牛这个问题就变得非常主观,直到一家线上排行榜诞生,它叫:LMArena。在文字、视觉、搜索、文生图、文生视频等不同的AI大模型细分领域,LMArena上每天都有上千场的实时对战,由普通用户来匿名投票选出哪一方的回答更好。