Genspark 发布 GenOffice:AI 时代的 Office,免费、开源,抢占办公人群的第一工作入口
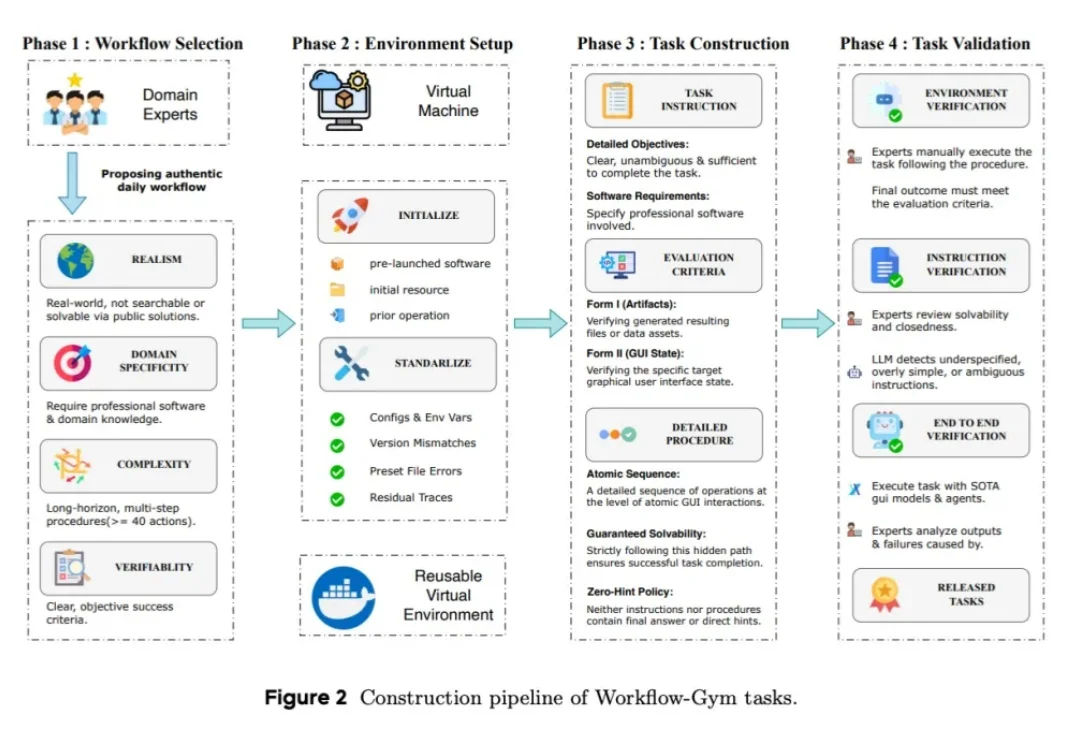
Genspark 发布 GenOffice:AI 时代的 Office,免费、开源,抢占办公人群的第一工作入口8 月 3 日,在 AGI Playground 2026 大会上,Genspark 创始人&CEO 景鲲在现场发布了一款新产品 GenOffice。这是一个面向 Windows 和 Mac 的本地 Office 客户端。开源、免费、无广告,保留用户熟悉的文档编辑能力,同时把 AI 引入 Word、PPT 等高频办公场景。
来自主题: AI资讯
8558 点击 2026-08-03 12:51