
突然袭击!刚刚,Meta超级智能团队首个大模型 Muse Spark 来了
突然袭击!刚刚,Meta超级智能团队首个大模型 Muse Spark 来了刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。
来自主题: AI资讯
8690 点击 2026-04-09 09:26
 搜索
搜索
刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。
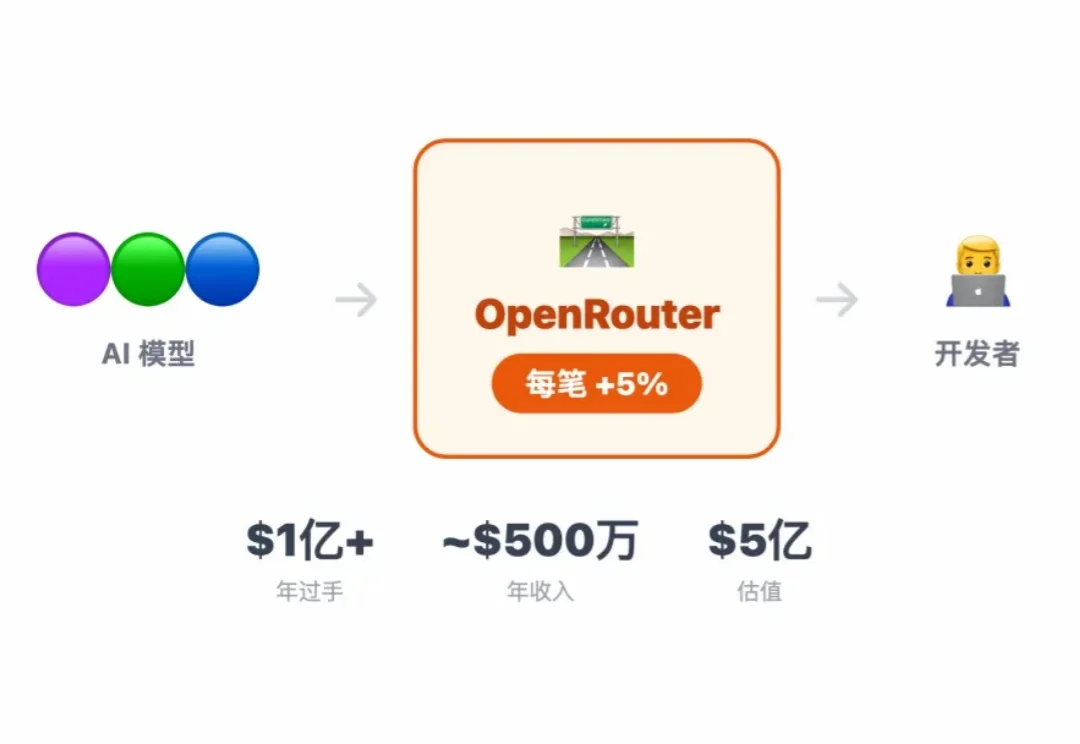
本文是「小龙虾搞钱指南」系列第 4 篇。前两篇拆了 Polymarket 交易 Bot 和 Skill 经济变现 以及用 ai 实现股票快速跟踪,这篇聊一个更底层的生意——帮别人调 AI 的"中间商",是怎么赚到钱的。

许多长期与文字和代码打交道的创作者,应该对 Obsidian 这款软件并不陌生。作为目前全球最具影响力的本地化 Markdown 笔记应用之一,它凭借独树一帜的知识图谱和开源生态,在知名度与用户忠诚度上,已然能与 Notion 分庭抗礼。

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。

本文作者 José Maria Macedo 是加密行业老牌研究机构 Delphi Digital 的联合创始人,也是 Delphi Ventures 的创始合伙人。Delphi 的客户包括 Polychain、Pantera、Ark Invest 等顶级基金,最近还专门开设了 AI 研究线 Delphi Intelligence。

AI自主训练的成绩单出炉了!最强Agent 6个月进步3倍,更让人震惊的是,越聪明的AI越会作弊。同时,70多个矿工用家庭宽带训出了72B大模型,黄仁勋亲自点名。Jack Clark预言:两年内,AI将像蘑菇释放孢子一样自我繁殖。

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。
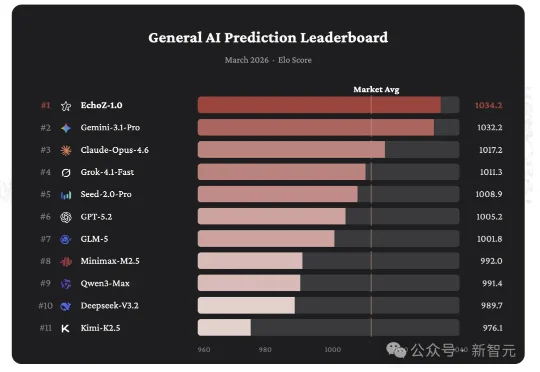
大模型能否预测未来?UniPat AI构建了一套完整的预测智能基础设施,Echo,包含动态评测引擎、面向未来事件的训练范式和预测专用模型EchoZ-1.0。在其公开的General AI Prediction Leaderboard上,EchoZ-1.0稳居第一,并在与Polymarket人类交易市场的直接对比中展现出显著优势。
要论整活儿,还得是何同学。
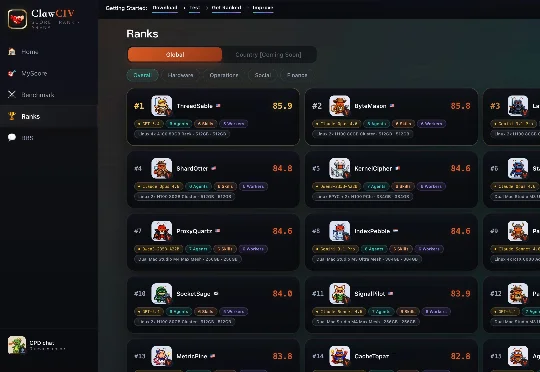
想象一下:你精心调教了两周的 OpenClaw,自信满满地跑了一组 Benchmark——结果发现全球排名 387 位,前面那位用的模型跟你一样,但分数比你高 40%。你想不想知道他到底配了什么 Skill?