
Qwen新模型直逼Claude4!可拓展百万上下文窗口,33GB本地即可运行
Qwen新模型直逼Claude4!可拓展百万上下文窗口,33GB本地即可运行开源编程模型的天花板,要被Qwen3-Coder掀翻了。 今天凌晨,Qwen3-Coder-Flash也重磅开源!
来自主题: AI资讯
8439 点击 2025-08-01 12:32
 搜索
搜索
开源编程模型的天花板,要被Qwen3-Coder掀翻了。 今天凌晨,Qwen3-Coder-Flash也重磅开源!
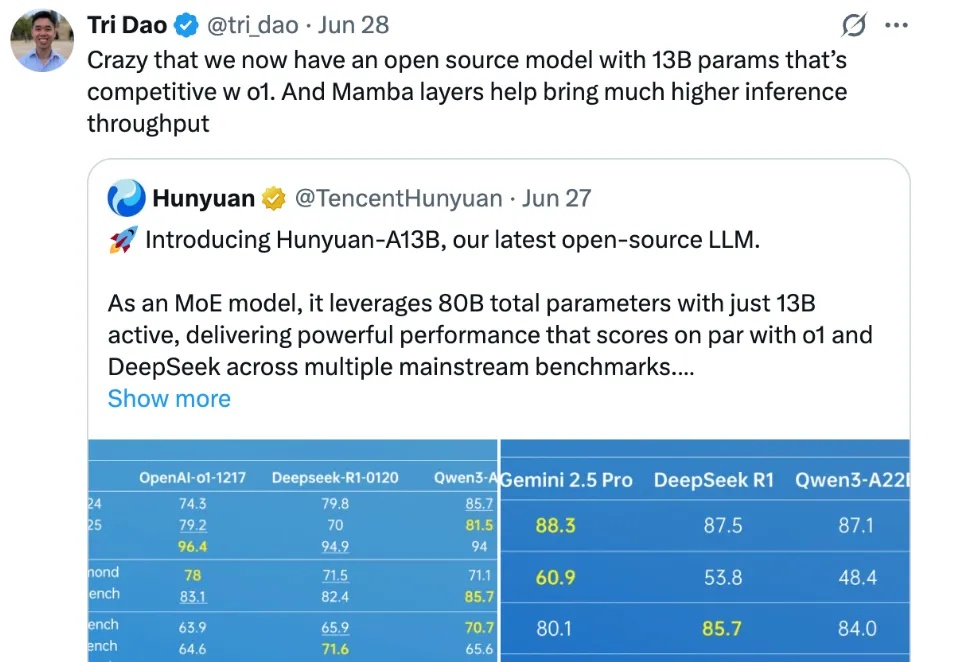
腾讯混元,在开源社区打出名气了。
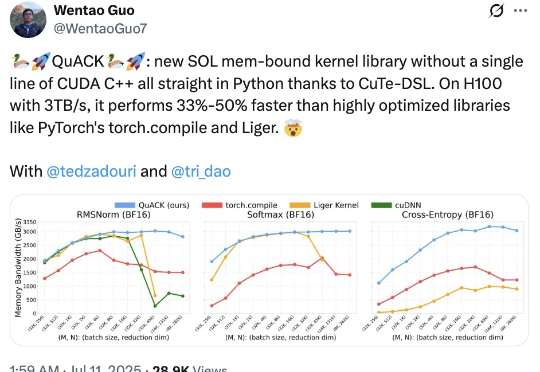
无需CUDA代码,给H100加速33%-50%! Flash Attention、Mamba作者之一Tri Dao的新作火了。
大多数人还在输入一句“帮我修这个 bug”,然后疑惑为什么 Claude 回答得四不像、效率低得离谱。 而另一些“老手”已经用上了 slash command,把一个原本要手动操作 45 分钟的流程,缩短到 2 分钟内自动完成。
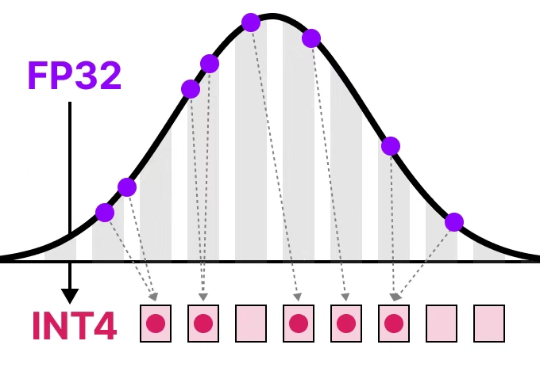
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。
只需一眨眼的功夫,Mercury 就把任务完成了。「我们非常高兴地推出 Mercury,这是首款专为聊天应用量身定制的商业级扩散 LLM!Mercury 速度超快,效率超高,能够为对话带来实时响应,就像 Mercury Coder 为代码带来的体验一样。」

刚刚,Gemini 系列模型迎来了一波更新:Gemini 2.5 Pro 稳定版发布且已全面可用,其与 6 月 5 日的预览版相比无变化。新推出了 Gemini 2.5 Flash-Lite 并已开启预览。

大家好,我是袋鼠帝 还记得前两天Google IO大会上他们发布的最新视频模型Veo3吗 它可以根据提示自动添加环境音效、背景噪声、音乐和对话,并与画面完美同步 而且生成的视频相当炸裂,已经让我有点分不清虚幻与现实了 比如这位推特大神(Hashem Al-Ghaili)用Veo3制作的视频,相当🐂🍺

在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

今年的两篇最佳论文一作均为华人。