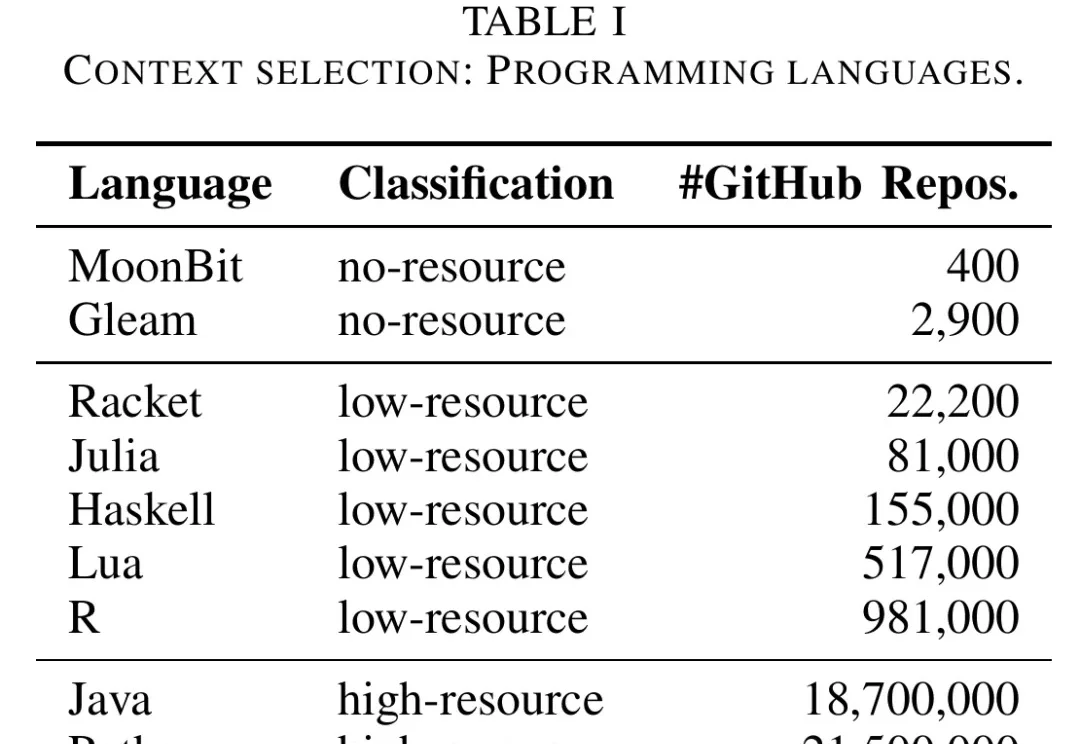
史上最高调的AI重写:Claude花11天搞定Bun,创始人花一个月才敢交底
史上最高调的AI重写:Claude花11天搞定Bun,创始人花一个月才敢交底这个 JavaScript 运行时原本拥有 535,496 行 Zig 代码,不包括注释;同时,约 20% 的代码由 C++ 编写,并嵌入了多个 C/C++ 库。此次借助 AI 重写为 Rust,整个过程涉及超过 100 万行代码变更、6778 次提交,并在 Claude Code 中运行了大约 50 个动态工作流(dynamic workflows)。
来自主题: AI资讯
8154 点击 2026-07-09 17:06