给语音模型戴上「眼镜」,错误率降低12.5%!人大CMU最新开源 | AAAI 2025
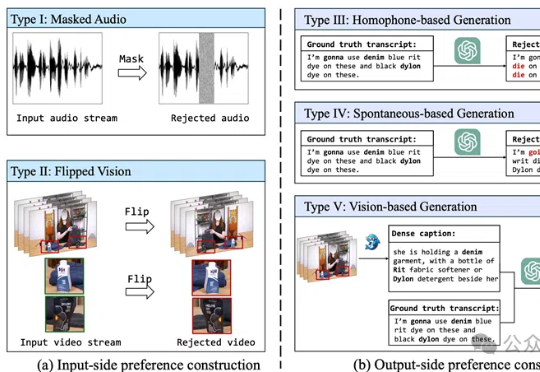
给语音模型戴上「眼镜」,错误率降低12.5%!人大CMU最新开源 | AAAI 2025视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。
来自主题: AI技术研报
8837 点击 2025-03-24 16:01
 搜索
搜索
视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。