
突破单链思考上限,清华团队提出原生「并行思考」scale范式
突破单链思考上限,清华团队提出原生「并行思考」scale范式近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
来自主题: AI技术研报
8237 点击 2025-09-18 14:49
 搜索
搜索
近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。
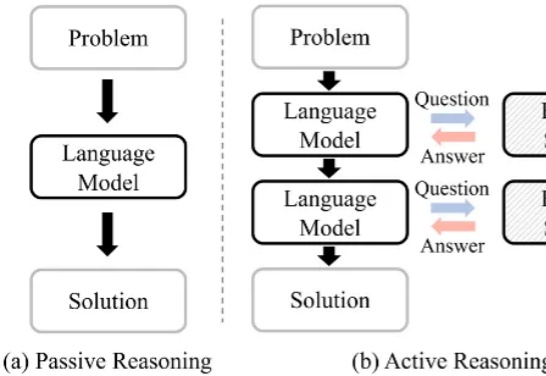
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。
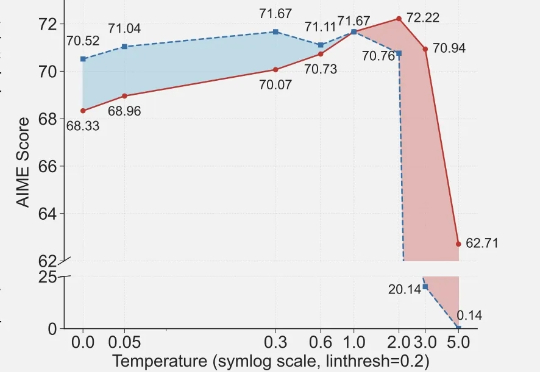
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果: 在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。
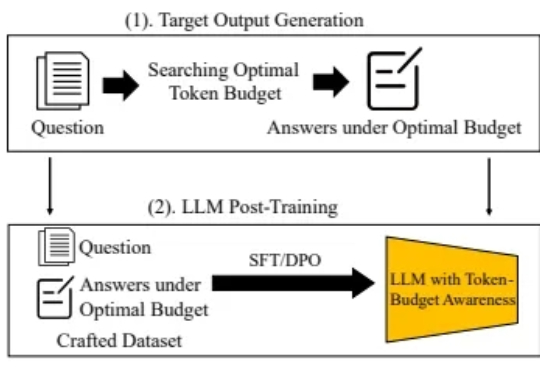
随着大型语言模型(LLM)技术的不断发展,Chain-of-Thought(CoT) 等推理增强方法被提出,以期提升模型在数学题解、逻辑问答等复杂任务中的表现,并通过引导模型逐步思考,有效提高了模型准确率。
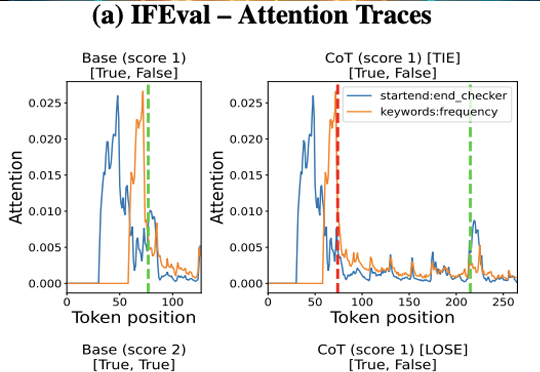
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!

《Why We Think》。 这就是北大校友、前OpenAI华人VP翁荔所发布的最新万字长文—— 围绕“测试时计算”(Test-time Compute)和“思维链”(Chain-of-Thought,CoT),讨论了如何通过这些技术显著提升模型性能。
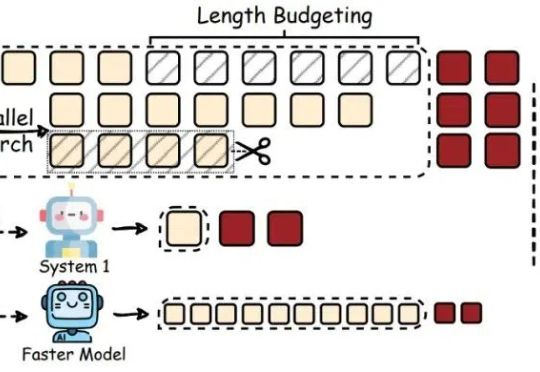
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。
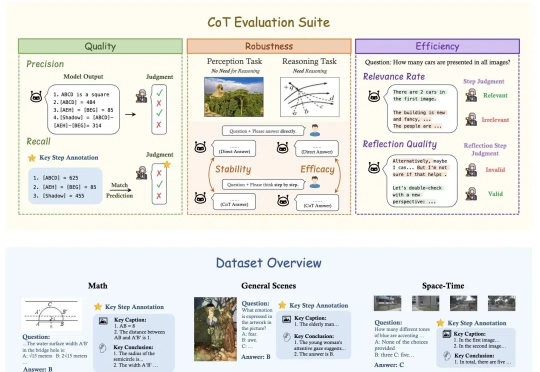
OpenAI o1和DeepSeek-R1靠链式思维(Chain-of-Thought, CoT)展示了超强的推理能力,但这一能力能多大程度地帮助视觉推理,又应该如何细粒度地评估视觉推理呢?