断供?会“刻意练习”的Qwen2.5-3B,竟然超越Claude3.5!斯坦福最新
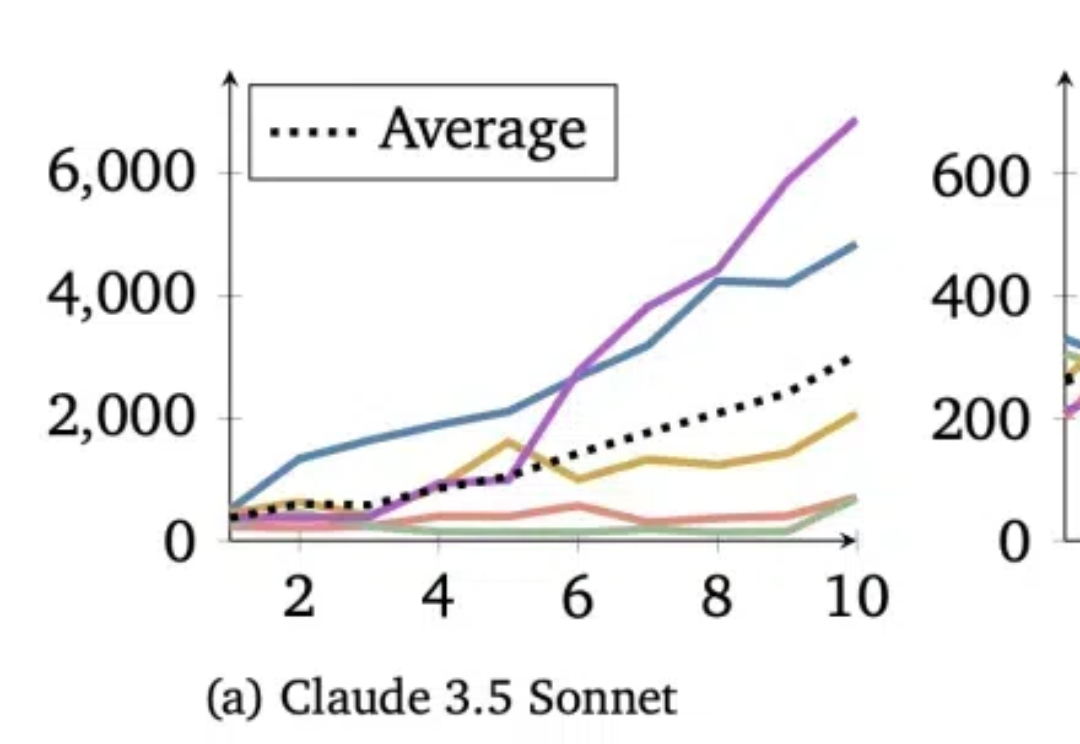
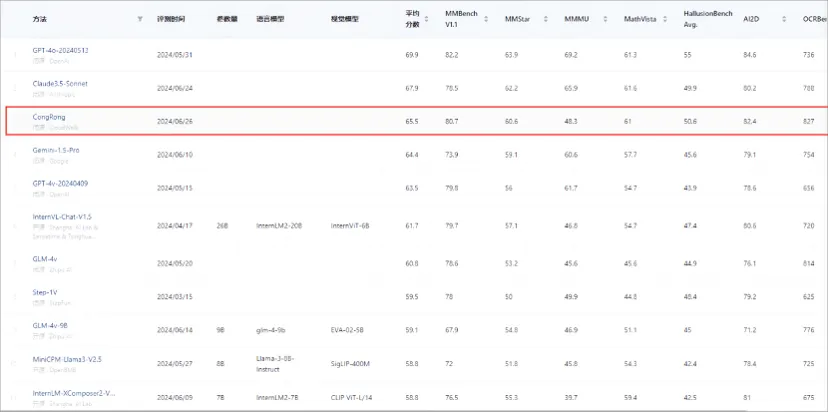
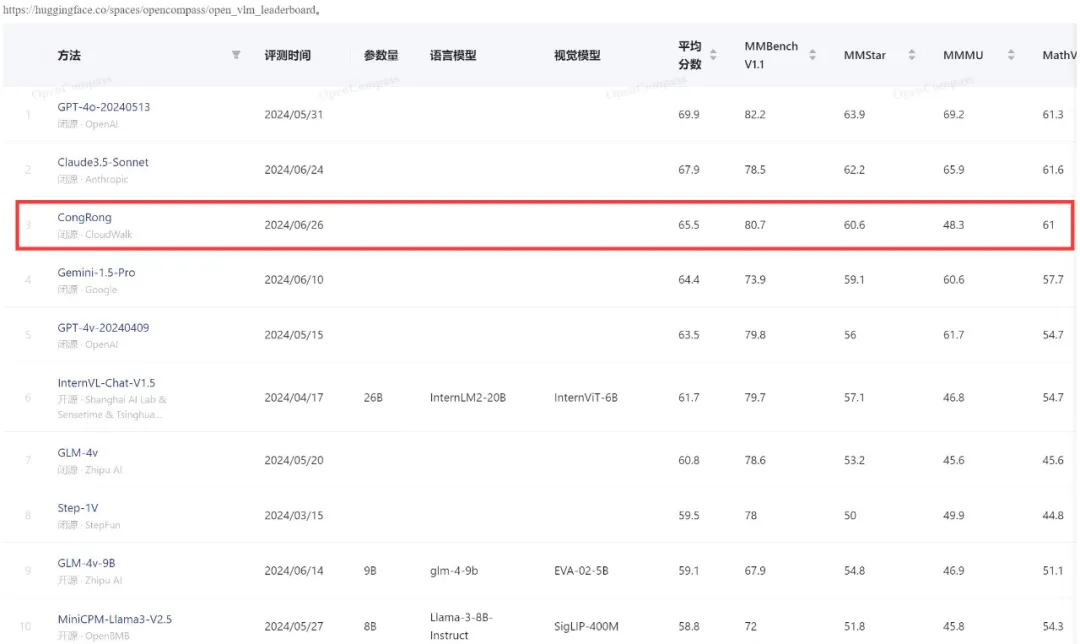
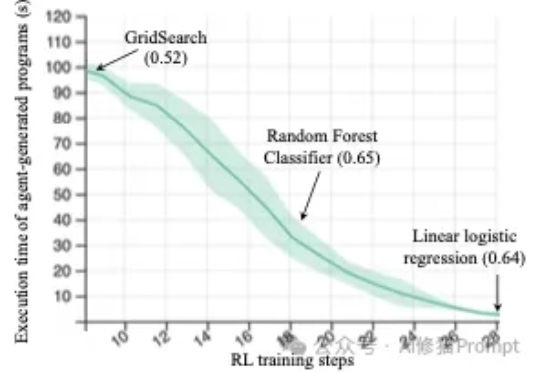
断供?会“刻意练习”的Qwen2.5-3B,竟然超越Claude3.5!斯坦福最新来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。
来自主题: AI资讯
9004 点击 2025-09-06 11:35