
提速199倍!清华&哈佛发布三维语义高斯泼溅LangSplat|CVPR‘24 Highlight
提速199倍!清华&哈佛发布三维语义高斯泼溅LangSplat|CVPR‘24 Highlight入选CVPR 2024 Highlight的三维语义高斯泼溅最新成果,查询速度比之前的SOTA方法LERF快了199倍!
来自主题: AI技术研报
11640 点击 2024-06-23 20:03
 搜索
搜索
入选CVPR 2024 Highlight的三维语义高斯泼溅最新成果,查询速度比之前的SOTA方法LERF快了199倍!
按部就班 vs. 好奇心驱动,哪个更容易出研究成果?
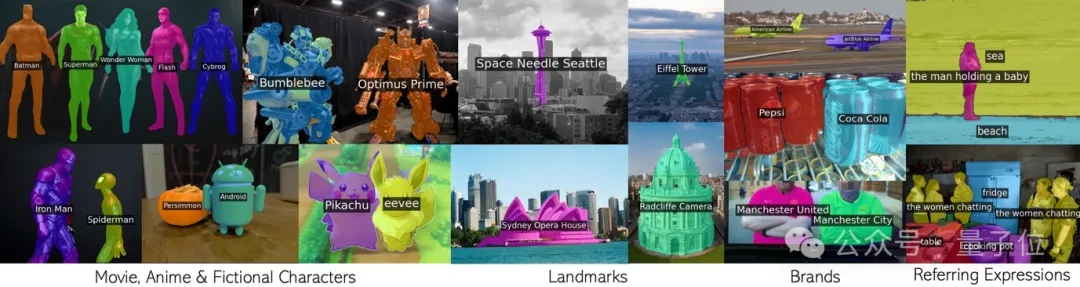
循环调用CLIP,无需额外训练就有效分割无数概念。 包括电影动漫人物,地标,品牌,和普通类别在内的任意短语。

自2021年诞生,CLIP已在计算机视觉识别系统和生成模型上得到了广泛的应用和巨大的成功。我们相信CLIP的创新和成功来自其高质量数据(WIT400M),而非模型或者损失函数本身。虽然3年来CLIP有大量的后续研究,但并未有研究通过对CLIP进行严格的消融实验来了解数据、模型和训练的关系。

一支人大系大模型团队,前后与OpenAI进行了三次大撞车!

CLIP长文本能力被解锁,图像检索任务表现显著提升!一些关键细节也能被捕捉到。上海交大联合上海AI实验室提出新框架Long-CLIP。

近年来,LLM 已经一统所有文本任务,展现了基础模型的强大潜力。一些视觉基础模型如 CLIP 在多模态理解任务上同样展现出了强大的泛化能力,其统一的视觉语言空间带动了一系列多模态理解、生成、开放词表等任务的发展。然而针对更细粒度的目标级别的感知任务,目前依然缺乏一个强大的基础模型。

AI长视频平台Clipfly(www.clipfly.ai)正式上线。Clipfly是Fotor旗下的新产品,集合了AI视频生成、AI视频增强、视频编辑等众多功能,是全球率先正式上线的一站式AI长视频平台。

来自纽约大学和UC伯克利的研究团队成功捕捉到了多模态大模型在视觉理解方面存在的重大缺陷。针对这个问题,他们进一步提出了一个将DINOv2特征与CLIP特征结合的方法,有效地提升了多模态大模型的视觉功能。

本文介绍了一个名为Alph-CLIP的框架,它在原始的接受RGB三通道输入的CLIP模型的上额外增加了一个alpha通道。在千万量级的RGBA-region的图像文本对上进行训练后,Alpha-CLIP可以在保证CLIP原始感知能力的前提下,关注到任意指定区域。通过替换原始CLIP的应用场景,Alpha-CLIP在图像识别、视觉-语言大模型、2D乃至3D生成领域都展现出强大作用。