o1之后下一个范式?隐式CoT大突破,让推理不再「碎碎念」
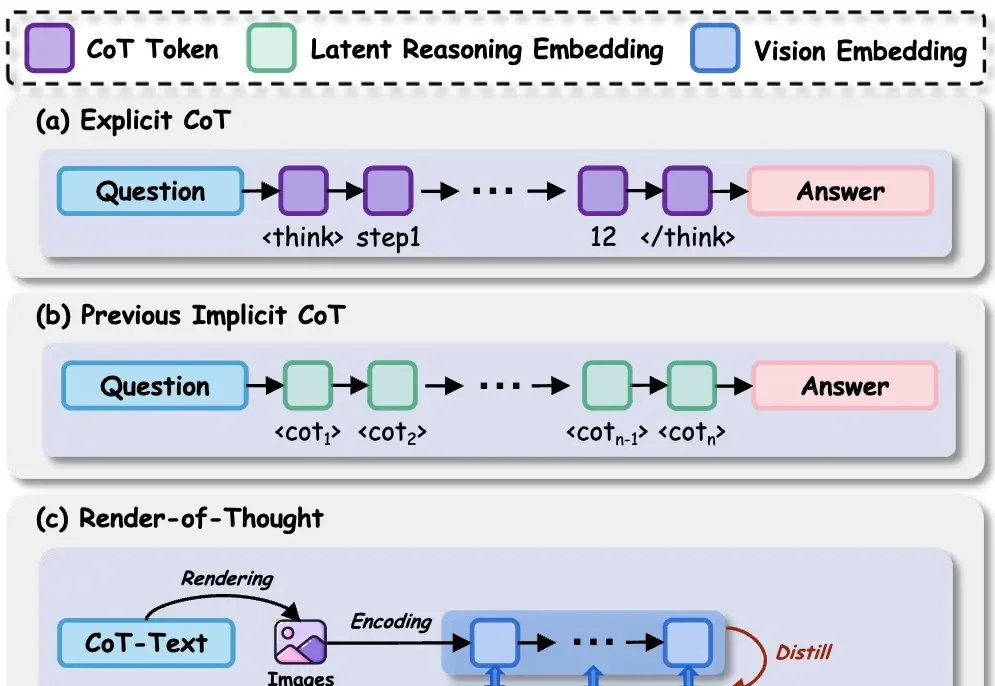
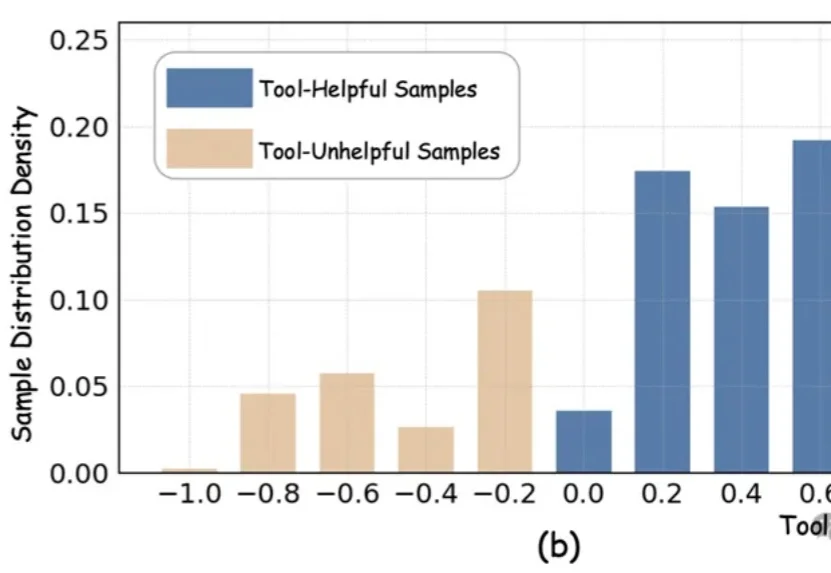
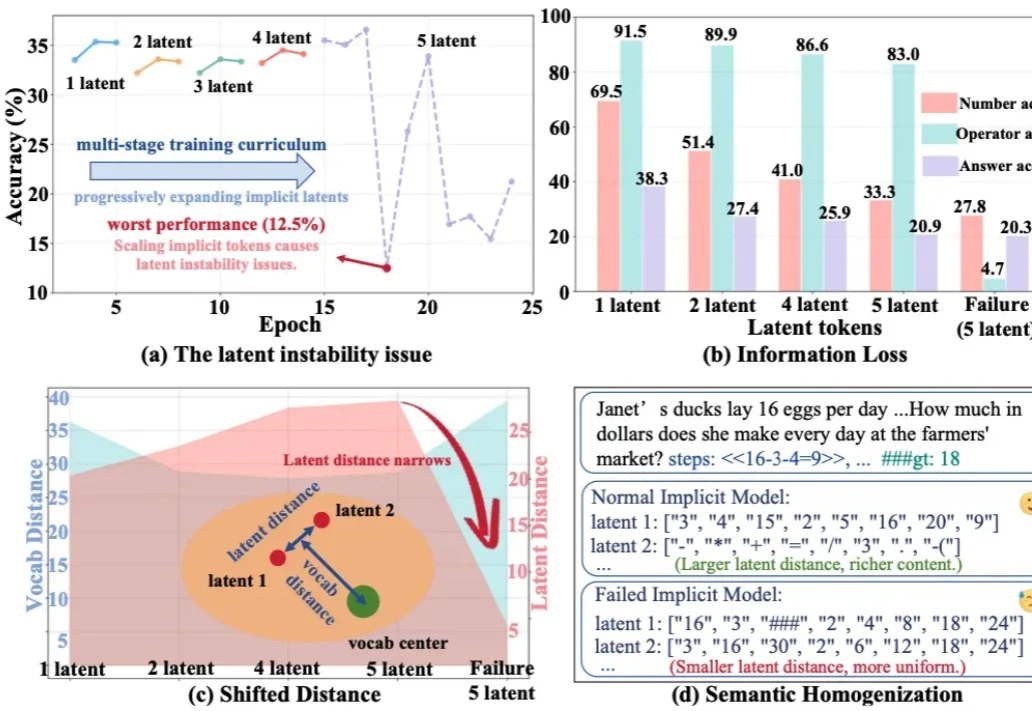
o1之后下一个范式?隐式CoT大突破,让推理不再「碎碎念」今天推荐一个 Implicit Chain-of-Thought(隐式推理) 的最新进展 —— SIM-CoT(Supervised Implicit Chain-of-Thought)。它直击隐式 CoT 一直「扶不起来」的核心痛点:隐式 token 一旦 scale 上去,训练就容易塌缩到同质化的 latent 状态,推理语义直接丢失。
来自主题: AI技术研报
7764 点击 2026-02-02 09:31