
半小时,轻松打造你的私人版免费 DeepResearch
半小时,轻松打造你的私人版免费 DeepResearch2025 年初,OpenAI、Perplexity、xAI 等 AI 公司都相继推出 Deep(Re)Search 功能。交给模型慢慢思考从而得到更详细的回答,成为了新潮流。
来自主题: AI资讯
10334 点击 2025-03-18 11:10
 搜索
搜索
2025 年初,OpenAI、Perplexity、xAI 等 AI 公司都相继推出 Deep(Re)Search 功能。交给模型慢慢思考从而得到更详细的回答,成为了新潮流。

3月17日上午,零一万物发布万智企业大模型平台,并宣布全面拥抱DeepSeek。这是继DeepSeek引发行业巨震后,作为大模型六小虎之一的零一万物首次对外发声。李开复明确表示,公司的未来重点方向在于ToB业务。虎嗅获悉,零一万物将在2025年进行战略收缩,并尽快完成战略聚焦,资源向ToB大力倾斜。

DeepSeek爆火续写了AI行业的神话,但融资时对标OpenAI的百川智能,却并未迎来春天。
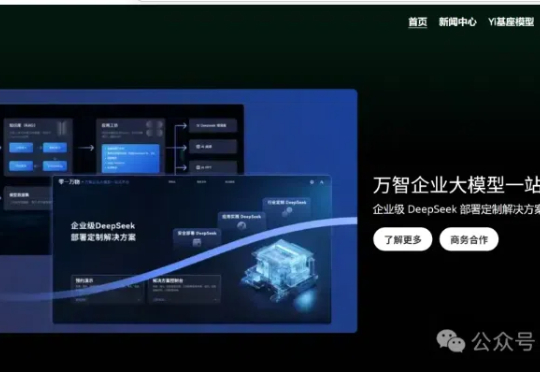
第一家全面拥抱DeepSeek的“六小虎”,出现了! 不卖关子,它就是李开复亲任CEO的零一万物。 今日正式上线万智企业大模型一站式平台,宣布提供企业级DeepSeek部署定制解决方案。
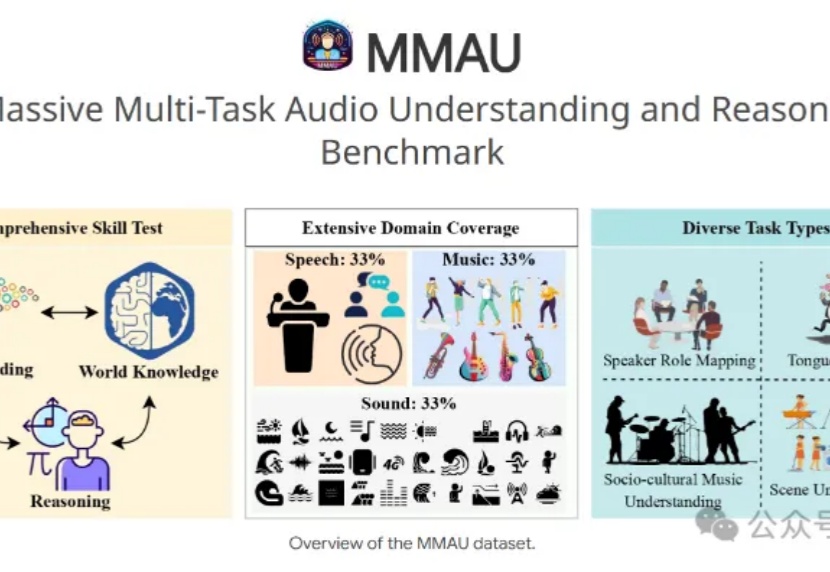
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

和DeepSeek等从大模型开始构建底层能力的AI公司不同,Manus AI是一家从day 1就只做AI应用的创业公司。
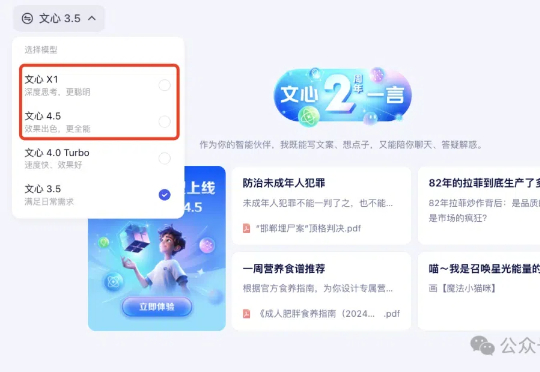
百度文心大模型重磅更新,刚刚如期而至。
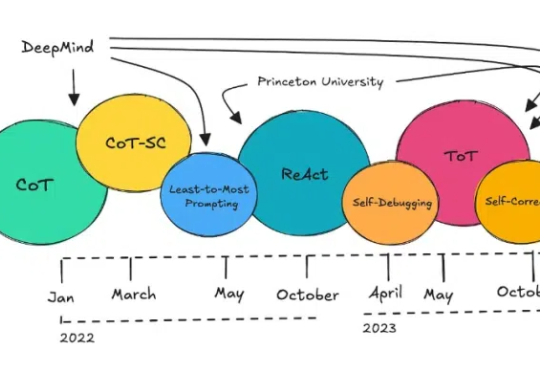
近段时间,推理模型 DeepSeek R1 可说是 AI 领域的头号话题。用过的都知道,该模型在输出最终回答之前,会先输出一段思维链内容。这样做可以提升最终答案的准确性。
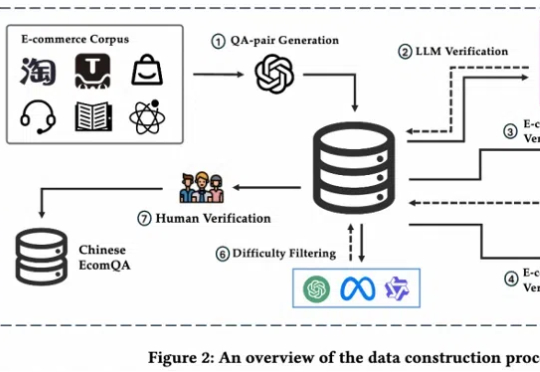
全面评估大模型电商领域能力,首个聚焦电商基础概念的可扩展问答基准来了!
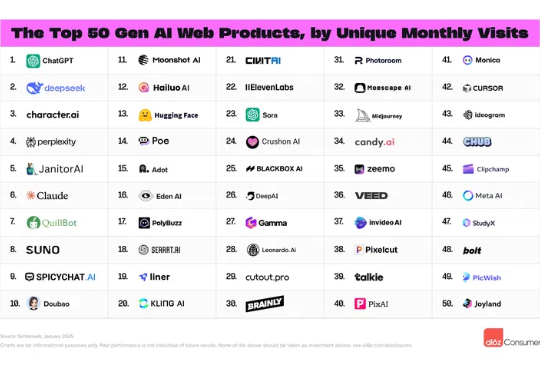
DeepSeek对中国创投圈的冲击,远比ChatGPT要来得更猛烈也更实际。