
Manus大升级,100多个智能体并发给你做任务
Manus大升级,100多个智能体并发给你做任务本周四,知名初创公司 Manus 推出了一项重要新功能,可以通过向上百协同工作的 AI 智能体分配任务来进行广泛的研究。今年早些时候,Manus 的多智能体平台改变了人们应用 AI 工具的方式。不过现在,这家创业公司正在试图开发一种与大模型深度思考 Deep Research 同样重要的新能力。
来自主题: AI资讯
11943 点击 2025-08-01 09:48
 搜索
搜索
本周四,知名初创公司 Manus 推出了一项重要新功能,可以通过向上百协同工作的 AI 智能体分配任务来进行广泛的研究。今年早些时候,Manus 的多智能体平台改变了人们应用 AI 工具的方式。不过现在,这家创业公司正在试图开发一种与大模型深度思考 Deep Research 同样重要的新能力。

谷歌DeepMind开启「上帝视角」,全新力作AlphaEarth Foundations震撼上线,10米级分辨率,打造出前所未有的地球数字画像。网友直呼:这不就是「地球版ChatGPT」?
科研是 AI 最早实现广泛落地的行业之一。在 ChatGPT 掀起这一轮生成式 AI 热潮之前,甚至可以追溯到上一轮由机器学习主导的技术浪潮中,AI 就已被用于气候模型参数校准、分子动力学模拟加速等科研任务。尤其在 2018 年前后,DeepMind 推出的 AlphaFold 在蛋白质结构预测方面实现突破,不仅引发了医药行业的技术革命,更被《自然》杂志评价为「解决了生物学五十年来的重大挑战」。

在ACL 2025的颁奖典礼上,由DeepSeek梁文锋作为通讯作者、与北京大学等联合发表的论文荣获最佳论文奖。 这次ACL 2025规模空前,总投稿量达到8360篇,相较于去年的4407篇几乎翻倍,竞争异常激烈 。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
ShowMeAI 参与了腾讯新闻热问年中《DeepSeek半年之后》专题策划,回顾上半年 AI 发展以及对多个行业的影响。
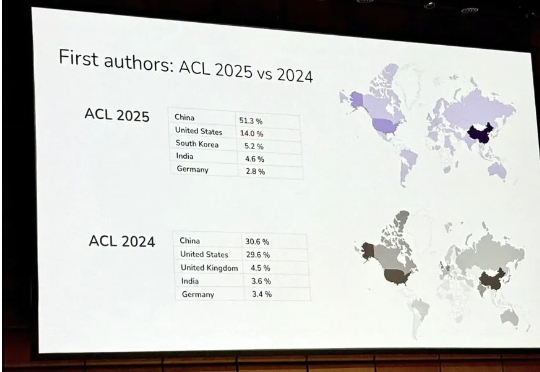
ACL 是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会组织,每年举办一次。一直以来,ACL 在 NLP 领域的学术影响力都位列第一,它也是 CCF-A 类推荐会议。今年的 ACL 大会已是第 63 届,于 2025 年 7 月 27 日至 8 月 1 日在奥地利维也纳举行。
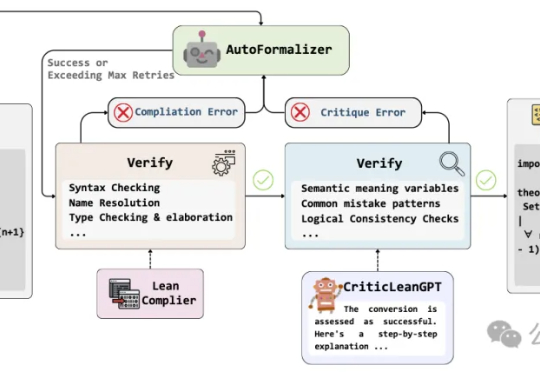
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。

在社交平台上,「AI 帮我选基金,结果赚了 8%」、「AI 自动炒股,秒杀巴菲特?」之类的帖子不时刷屏,炒股机器人、对话式理财助手有关的 Agent 也不断涌现。
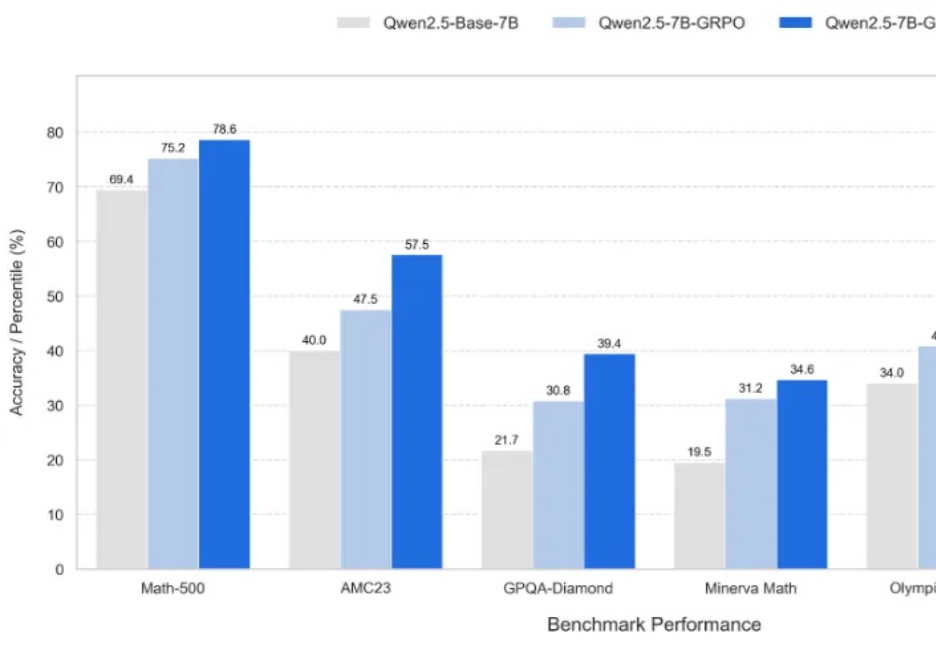
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。