首次结合RL与SFT各自优势,动态引导模型实现推理⾼效训练
首次结合RL与SFT各自优势,动态引导模型实现推理⾼效训练新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
来自主题: AI技术研报
8173 点击 2025-07-28 10:36
 搜索
搜索
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。

AI四小强(如MiniMax、月之暗面)在黄仁勋认可下重新入局,全推出Deep Research抢占AI Agent市场。面对大厂竞争,他们放弃用户规模追逐,转向技术迭代如模型升级(K2、M1等),并分化两种路径操作。需通过出圈应用证明价值,应对成本高、增长放缓的盈利压力。

放眼当下,到底哪个芯片跑满血DeepSeek是最快的? 答案很意外——不是你以为的英伟达,而是一家国产GPU。 因为现在它的速度,已经直接来到了100 tokens/s!

谷歌DeepMind不信邪。 这不前脚,谷歌刚获IMO金牌,小扎就光速挖走三名核心团队成员。 如此抓马又无语,更多人都劝谷歌DeepMind小心点儿吧,要不以后论文署名都匿名吧,实在不行学习中国互联网公司用花名吧……

前两周,广东某国企发了篇万字标文,以预算四十万招标一台DeepSeek一体机。 近乎30页的文档里,采购明细表短短6行,所需的芯片类型等关键指标,只字未提。“看这个标就知道,大家完全没把一体机用起来”,业内人士直言。
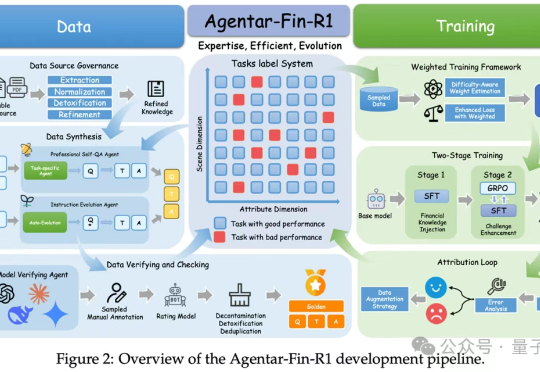
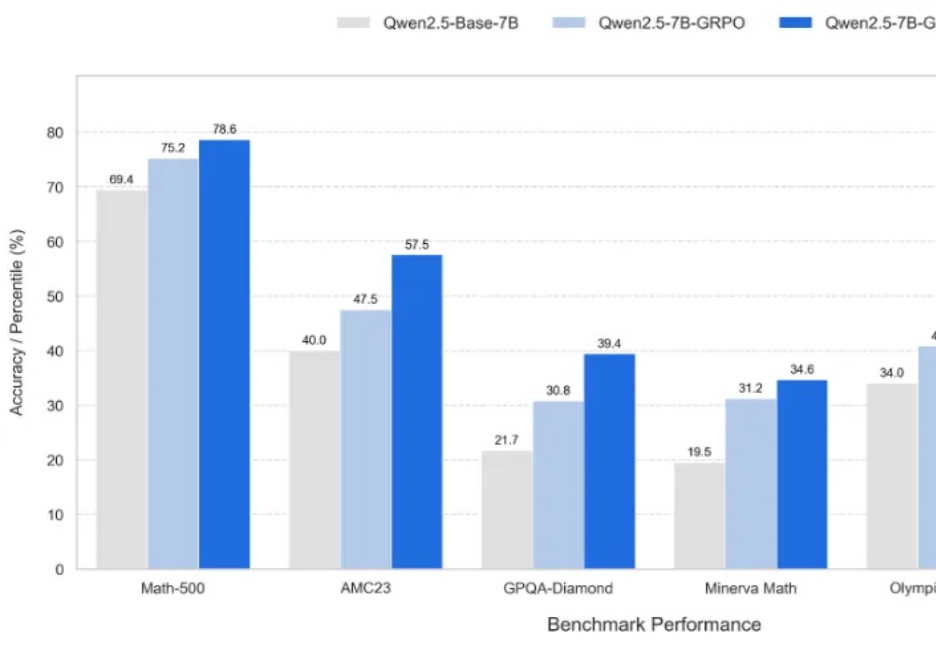
又到了一年一度“中国AI春晚”WAIC,各家大厂动作频发的时候。 今年会有哪些看点?你别说,我们还真在扒论文的过程中,发现了一些热乎线索。 比如蚂蚁数科的金融推理大模型,发布会还没开,技术论文已悄咪咪上线。 金融领域的推理大模型,你可以理解为金融领域的DeepSeek,带着SOTA的刷榜成绩来了。

如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。 就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。 Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。

无需复杂编程,仅通过观看视频就能破解光照、反射等物理规律。Hassabis畅想,在AI驱动的游戏世界,玩家每一步都将触发独特的故事,成为个人化的冒险乐园。

在正式走近ChatGPT Agent之前,让我们介绍一下这次谈话的几位主角,他们分别是OpenAI团队核心成员Isa Fulford、Casey Chu和孙之清。我们团队分别开发了Operator和Deep Research,在分析用户请求时发现,Deep Research的用户非常希望模型能够访问需要付费订阅的内容或有门槛的资源,而Operator恰好具备这种能力。
我们似乎正处在一个“收藏即掌握”的时代。 不管是知乎、论文库,还是小红书,只要看到一句金句、一篇好文、一个值得学习的案例,我们的第一反应往往是点个收藏,留着以后看。然而,我们真的会“回头再看”吗?