国内首个免费提供的深度研究,反而有市面上最好的体验
国内首个免费提供的深度研究,反而有市面上最好的体验大家好我是歸藏(guizang),今天给大家带来秘塔深度研究的体验。
来自主题: AI产品测评
11057 点击 2025-07-17 10:34
 搜索
搜索
大家好我是歸藏(guizang),今天给大家带来秘塔深度研究的体验。
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?

剧本杀大家都玩过吗?这是一种经典的桌上角色扮演游戏(TTRPG), 游戏中的核心人物是游戏主持人(GM), 相当于整个世界的「导演 + 编剧 + 旁白」,负责掌控游戏环境,讲述故事背景,并扮演所有非玩家角色(NPC)。
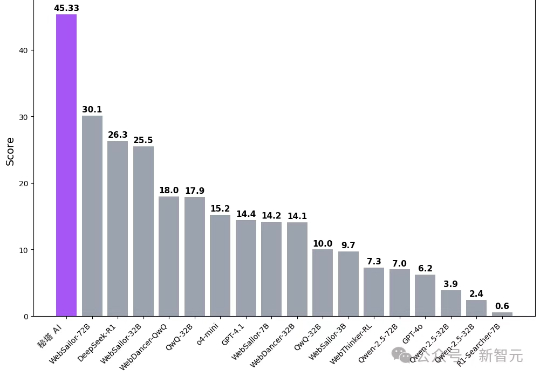
刚刚,国内首个免费可用Deep Research上线了!它在多个权威评测中拿下第一,准确率直接碾压开源WebSailor。研究过程中,它能多线迭代追搜,直至逻辑闭环。更绝的是,一键生成炫酷的互动研究报告,视觉效果直接拉满。

太卷了,卷麻了! 对标海外的Deep Research(深度研究)功能,现在咱国内,免费,想咋用就咋用。

最近大家有没有发现,好多店家开始用 DeepSeek 来营销了?
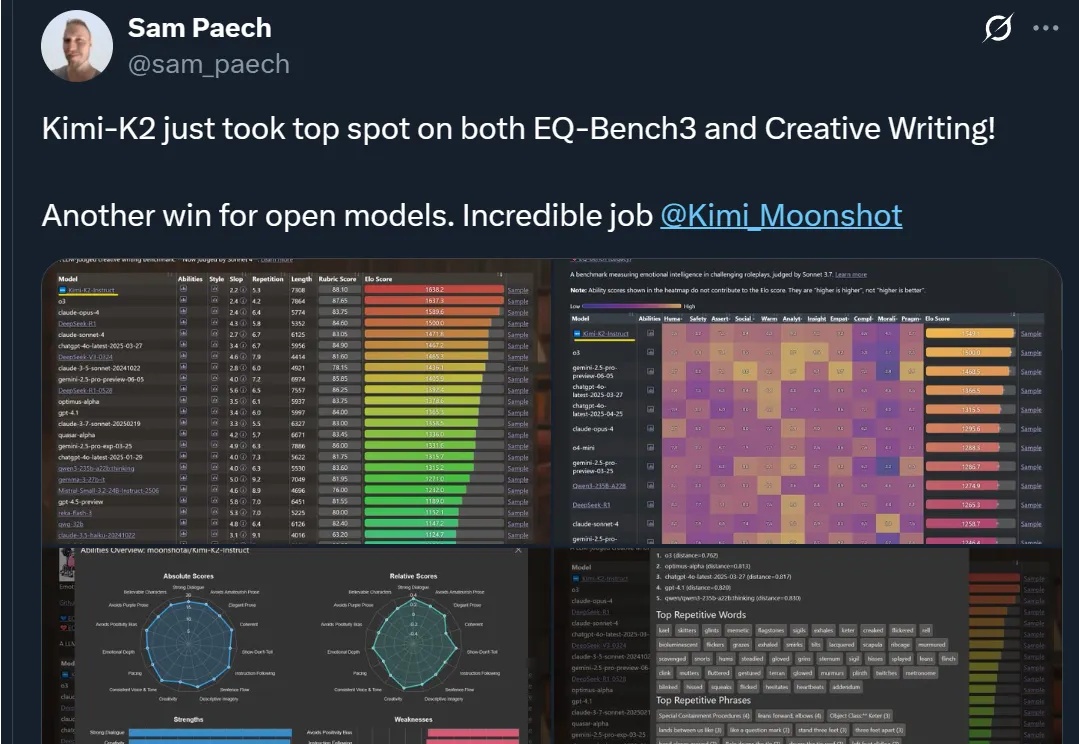
Kimi新模型热度持续高涨ing!
昨天晚上,秘塔AI搜索悄悄上了一个新功能。测试完以后,我觉得这玩意,还是值得我将近通宵写一篇的。
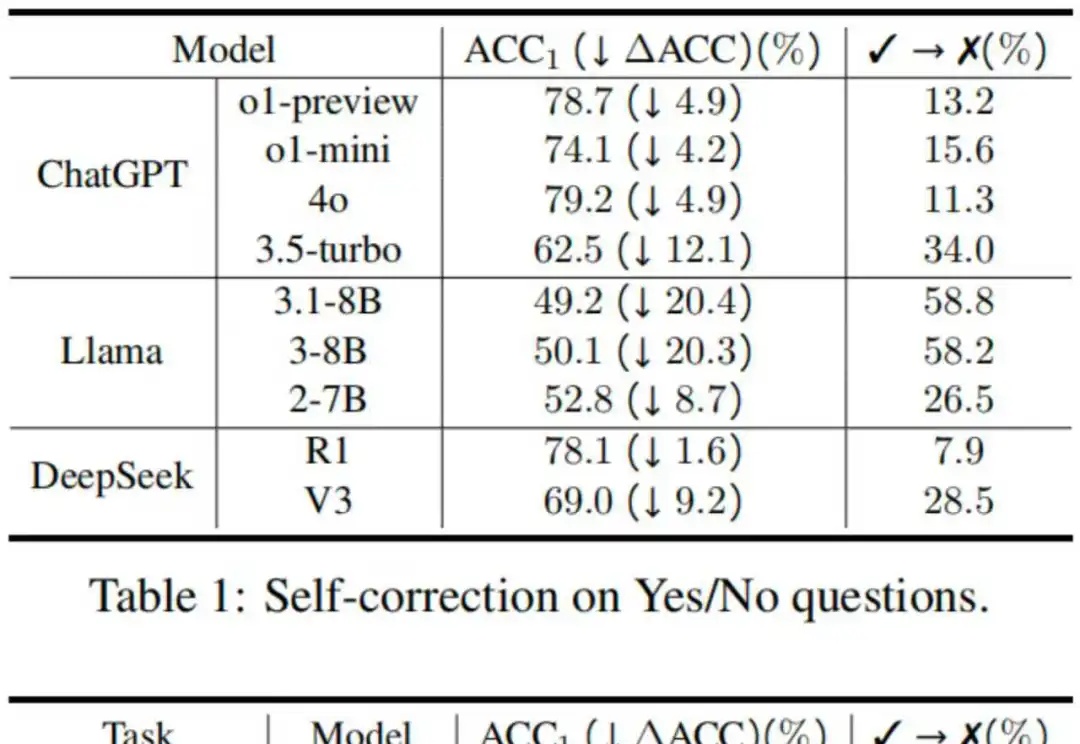
反思技术因其简单性和有效性受到了广泛的研究和应用,具体表现为在大语言模型遇到障碍或困难时,提示其“再想一下”,可以显著提升性能 [1]。然而,2024 年谷歌 DeepMind 的研究人员在一项研究中指出,大模型其实分不清对与错,如果不是仅仅提示模型反思那些它回答错误的问题,这样的提示策略反而可能让模型更倾向于把回答正确的答案改错 [2]。
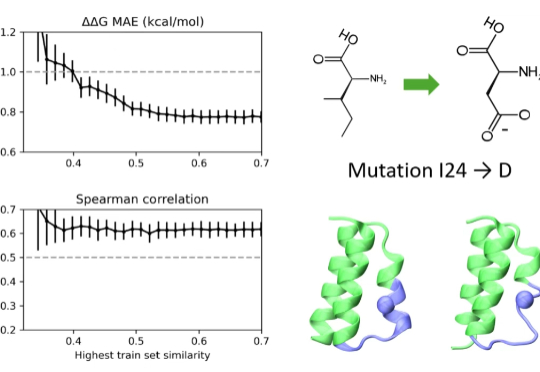
7 月 10 日,微软研究院 AI for Science 团队在《Science》杂志发表了题为「Scalable emulation of protein equilibrium ensembles with generative deep learning」的研究成果。