
谷歌IMO金牌级Gemini 3深夜上线!华人大神挂帅,OpenAI无力反击
谷歌IMO金牌级Gemini 3深夜上线!华人大神挂帅,OpenAI无力反击太劲爆了!不过半月,谷歌DeepMind终于放出了IMO最强金牌模型——Gemini 3 Deep Think。今天,Gemini 3 Deep Think已在Gemini App上线,所有Ultra用户即可体验。
来自主题: AI资讯
10067 点击 2025-12-05 12:38
 搜索
搜索
太劲爆了!不过半月,谷歌DeepMind终于放出了IMO最强金牌模型——Gemini 3 Deep Think。今天,Gemini 3 Deep Think已在Gemini App上线,所有Ultra用户即可体验。

正值AlphaFold问世五周年,其设计者、也是凭借AlphaFold获得诺贝尔化学奖的John Jumper公开表示:AlphaFold的下一步是与大模型融合。不过具体方法并没有透露,或许已有所思路,甚至已经在进程之中。
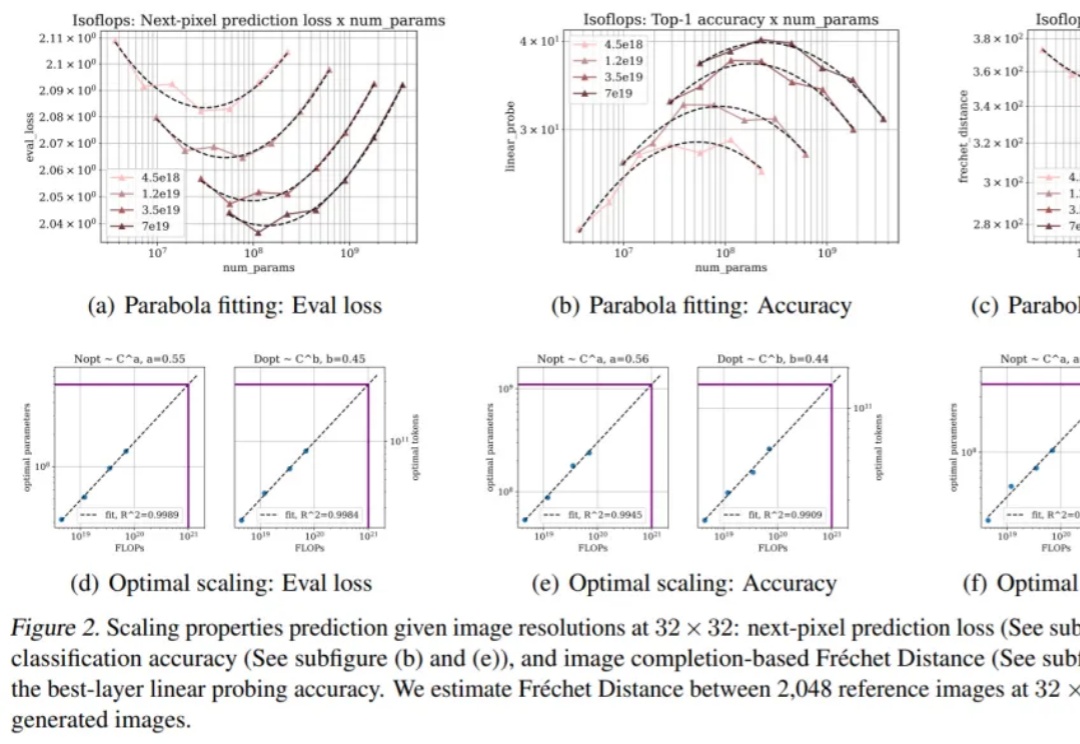
既然语言可以当序列来学,那图像能不能也当序列来学?

真·乘胜追击。
您的 AI 伙伴「游戏陪玩」版已上线。

11年前,谷歌收购DeepMind,花巨资买来一个「诺贝尔奖 + 顶级科学家 + 世界级实验室」,没想到却被OpenAI抢先推出ChatGPT,几乎动摇谷歌核心搜索业务,这一切背后的核心人物正是谷歌的AI掌门人哈萨比斯。
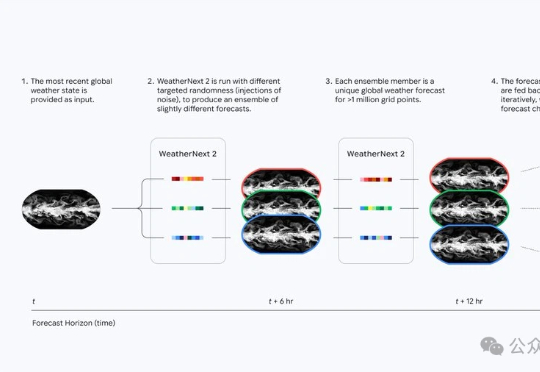
天气预报的时代真的变了。谷歌DeepMind最新发布的WeatherNext 2,让查天气这件事升级成了小时级、实时化。它的运行速度比上一代快8倍,分辨率提高到小时级,也就是说不再是传统预报里的“明天下午有雨”,而是可以细到“明天2–3点有小雨,3–4点雨势增强,5–6点逐渐停止”的节奏。

他被12所大学拒绝,签证差点作废。后又被DeepMind拒了三次,在亚马逊做着最不起眼的测试工作。十二年后,这个被世界反复拒绝的人,写出了改变AI格局的PyTorch。
如果一个AI,像人类一样看屏幕、敲键鼠、自己练级变强,这种游戏搭子,你愿意拥有吗?可能不久将来,类似王者荣耀、DOTA 2这样的游戏就可以选择和AI组队,而不是和人组队了!
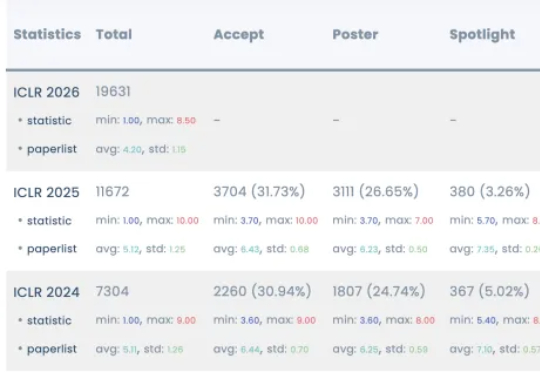
ICLR 2026评审结果震撼出炉:投稿量暴增至近2万篇,却迎来分数大滑坡,平均分从5.12跌至4.2。审稿人吐槽论文质量低下,甚至疑似AI生成,这场学术盛宴为何变味?