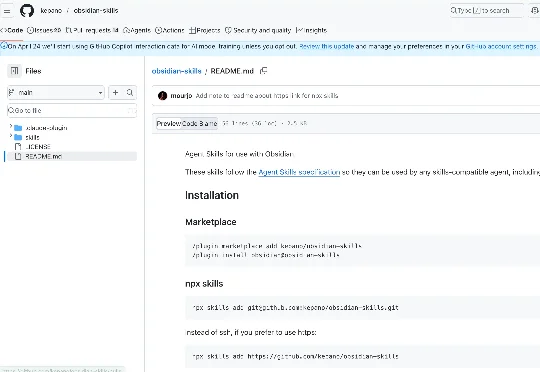
27k Stars,零行代码 —— kepano/obsidian-skills 凭什么?
27k Stars,零行代码 —— kepano/obsidian-skills 凭什么?随手打开 GitHub,2026 年的 Agent 项目热榜上有这样一个仓库: • 27,000+ stars,1,800+ forks • 零行 Python,零行 TypeScript,零行 JS • 作者是 Obsidian 的 CEO 本人,kepano • 整个仓库就是 5 个 Markdown 文件
来自主题: AI资讯
9402 点击 2026-05-09 10:34