ICML 2026 | 我们让蒸馏模型当了采样器,Diffusion RL采样成本降低一个数量级
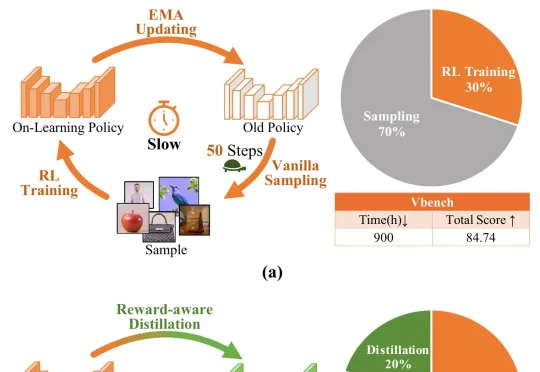
ICML 2026 | 我们让蒸馏模型当了采样器,Diffusion RL采样成本降低一个数量级过去的 Diffusion RL 多聚焦于奖励设计与优化算法,训练时的采样成本被忽视。DMSampler 指出:在在线 RL 中,限制规模化的不只是奖励信号或优化器,很多时候是 rollout 本身太贵。
来自主题: AI技术研报
7759 点击 2026-08-01 10:44
 搜索
搜索
过去的 Diffusion RL 多聚焦于奖励设计与优化算法,训练时的采样成本被忽视。DMSampler 指出:在在线 RL 中,限制规模化的不只是奖励信号或优化器,很多时候是 rollout 本身太贵。

袁博地的答案是否定的。从清华大学接触计算机视觉,到 UC Berkeley 攻读 AI 博士,再到 Google X 负责机器人的视觉系统,袁博地过去十多年的研究几乎始终围绕 Pixel 展开:从图像识别,到 GAN、Diffusion,再到图像和视频生成,技术范式不断变化,研究对象却始终指向同一件事——如何让机器理解和生成视觉世界。

还在用 DragGAN、DragDiffusion 拖拽修图?点选拖拽容易变形、边界割裂、细节丢失的时代落幕了!ECCV 2026 ICRDrag 首创上下文区域拖拽模型,用掩码精准定位局部区域,移动、缩放、变形全都丝滑自然,兼顾精准度与画面真实感。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。
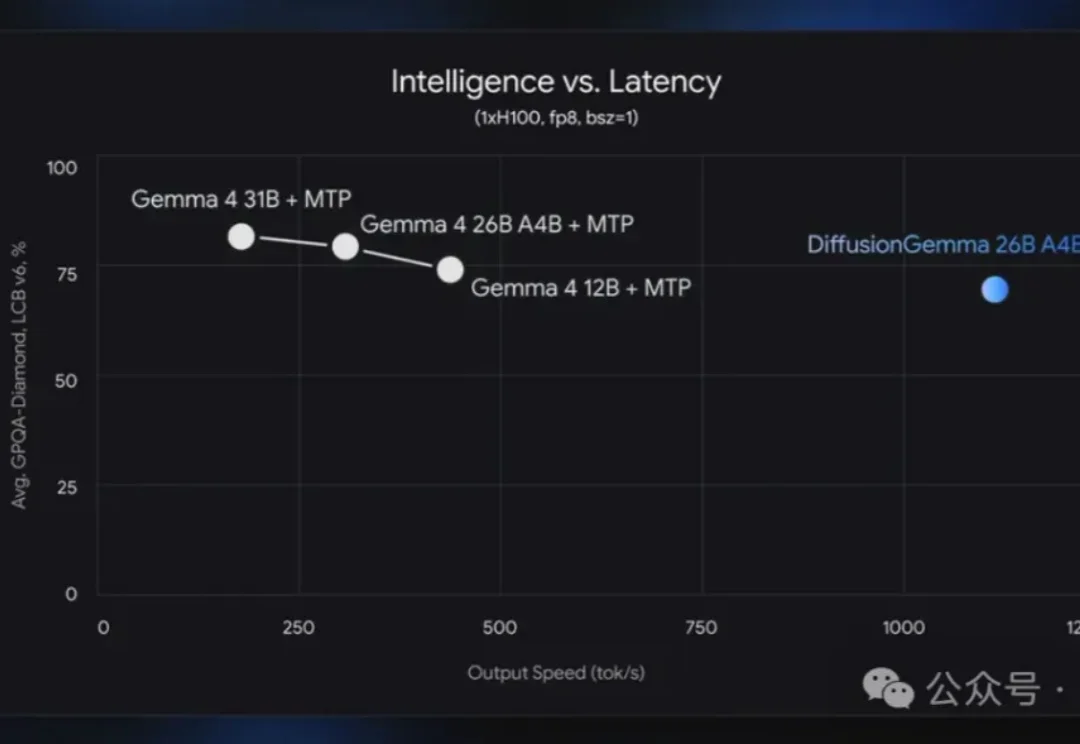
就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——

今天一早,谷歌又发新模型了!
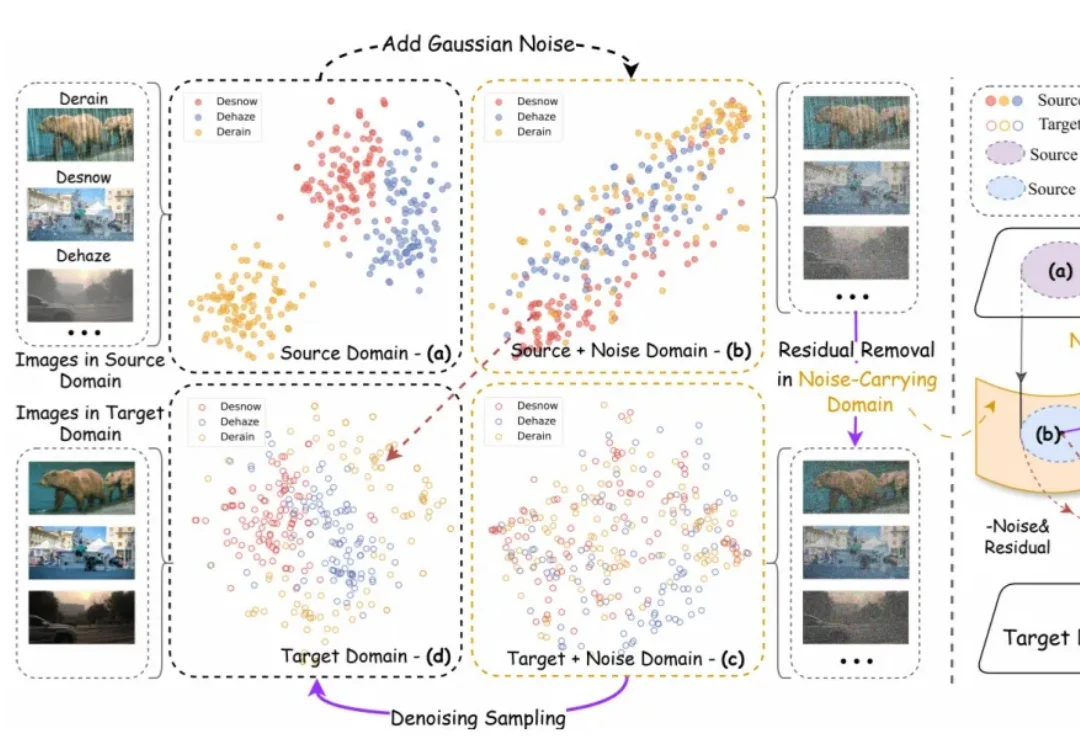
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。

2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。
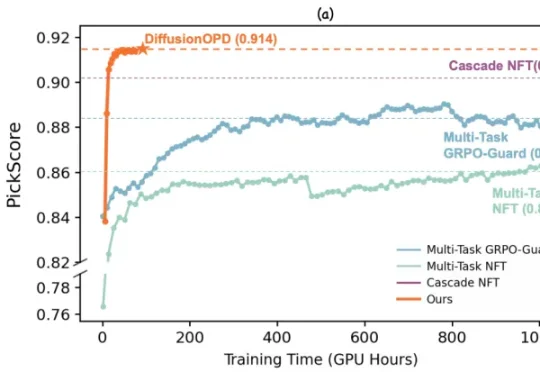
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。