扎克伯格还在疯狂抢夺AI人才:估值5亿美元收编AI公司Dreamer
扎克伯格还在疯狂抢夺AI人才:估值5亿美元收编AI公司DreamerMeta再次出手了。这次不是收购某个成熟产品,而是直接把整个团队连锅端走。
来自主题: AI资讯
10747 点击 2026-03-25 10:43
 搜索
搜索
Meta再次出手了。这次不是收购某个成熟产品,而是直接把整个团队连锅端走。

中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。

华为在世界模型上又有新动作:投了一家物理AI公司。

谷歌世界模型大牛Danijar Hafner宣布离任!他自2016年起开始在Google Brain实习,后又在DeepMind、Brain Team工作。他的经历颇具传奇色彩,曾获辛顿指导,还与Łukasz Kaiser、Ashish Vaswani等Transformer大佬有过交集。
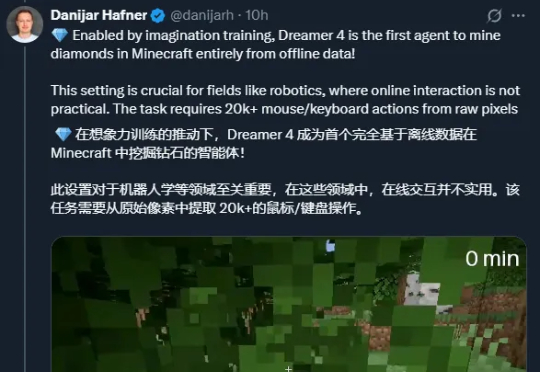
只让机器人或虚拟智能体「想象」,不让它们和物理世界交互,它们也能学到和世界交互的技能?谷歌的世界模型 Dreamer 4 为这一想法提供了新的支撑。为了在具身环境中解决复杂任务,智能体需要深入理解世界并选择成功的行动。世界模型通过学习从智能体(如机器人或电子游戏玩家)的视角预测潜在行动的未来结果,为实现这一目标提供了一种有前景的方法。

想象一下,一座生机勃勃的 3D 城市在你眼前瞬间成型 —— 没有漫长的计算,没有庞大的存储需求,只有极速的生成和惊人的细节。

谷歌DeepMind研发的DreamerV3实现重大突破:无需任何人类数据,通过强化学习与「世界模型」,自主完成《我的世界》中极具挑战的钻石收集任务。该成果被视为通往AGI的一大步,并已登上Nature。

在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?
人工智能技术正以前所未有的速度改变着我们对世界的认知与构建方式。近期,李飞飞教授团队通过单张图片生成三维物理世界的研究,再次向世界展示了空间智能技术的巨大潜力。

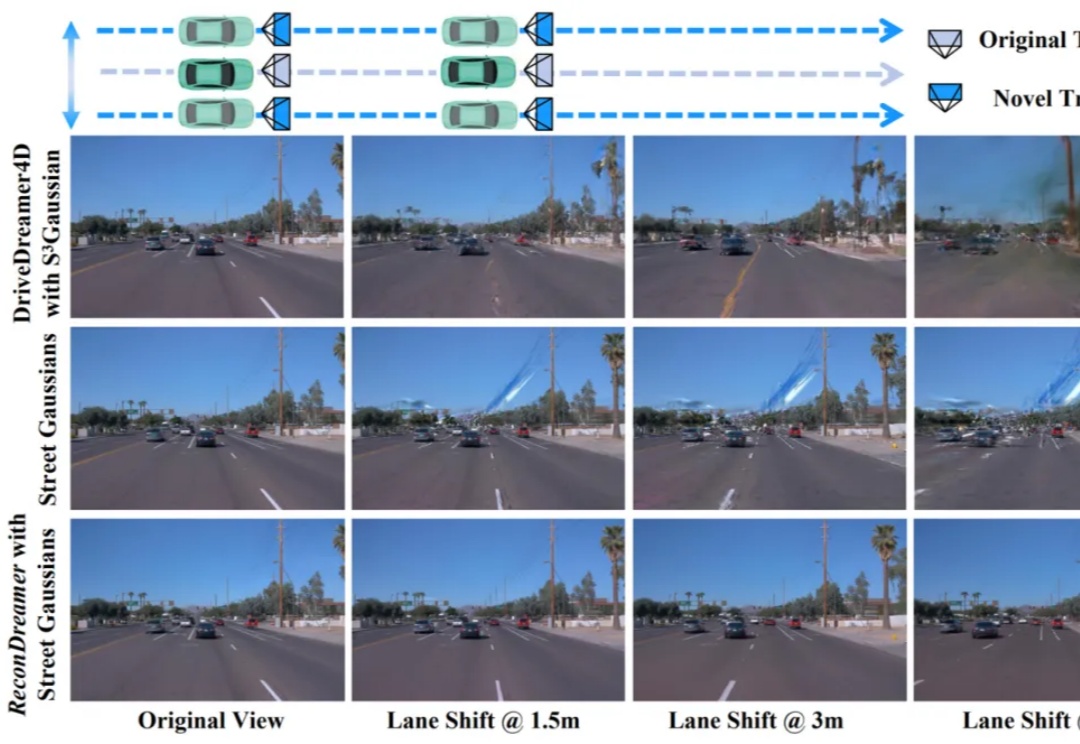
近日,极佳科技联合中国科学院自动化研究所、理想汽车、北京大学、慕尼黑工业大学等单位提出DriveDreamer4D,是首个利用世界模型增强 4D 驾驶场景重建效果的工作。