
拿完350万美元种子轮后,他们做了一款消费级神经干预AI耳机,众筹金额已达91w
拿完350万美元种子轮后,他们做了一款消费级神经干预AI耳机,众筹金额已达91w试图把医疗级脑刺激技术装进日常耳机。
来自主题: AI资讯
9944 点击 2026-07-13 15:28
 搜索
搜索
试图把医疗级脑刺激技术装进日常耳机。
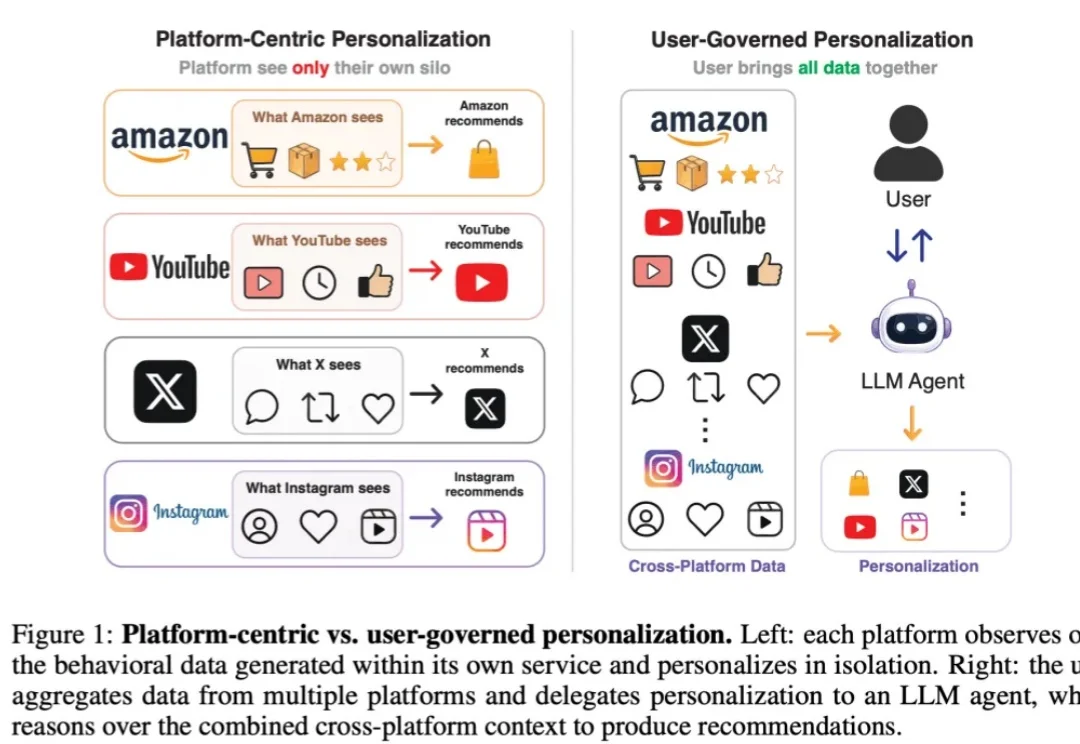
在过去二三十年的互联网发展中,个性化推荐几乎一直是平台的核心能力之一。打开视频 app,平台决定你接下来会刷到什么视频;打开购物软件,平台预测你可能会购买什么商品;打开短视频 app,平台根据你的浏览、点赞、停留和互动,不断优化信息流。某种意义上,现代互联网的用户体验本身就是由推荐系统塑造的。
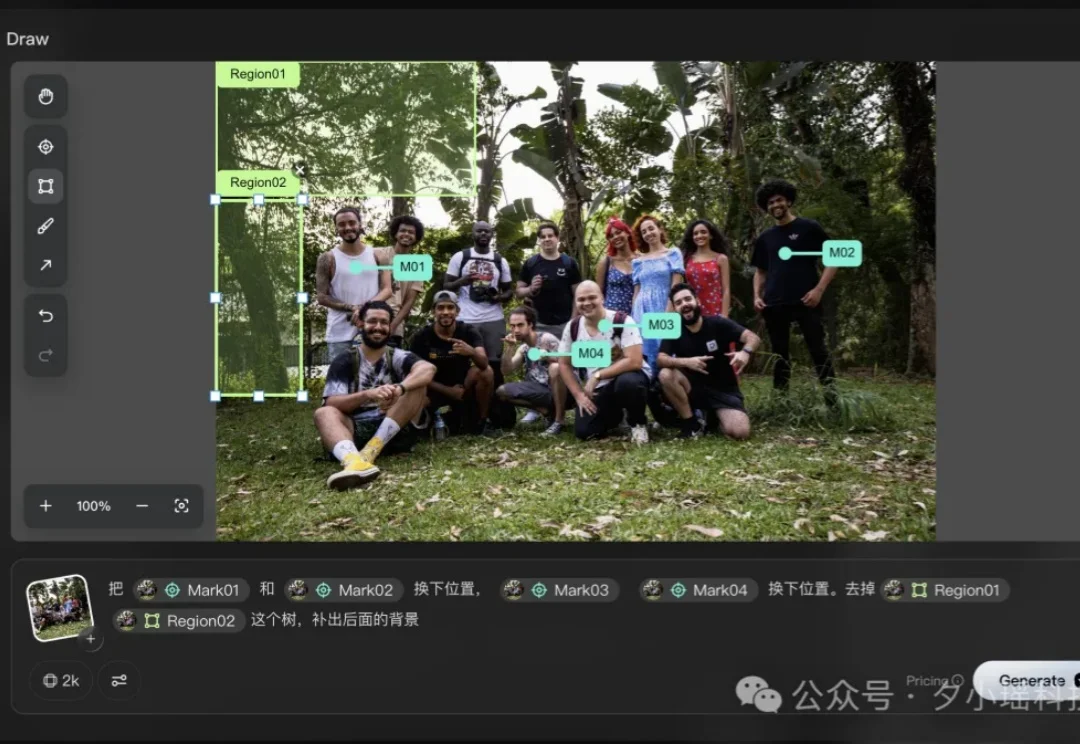
用 AI 生图的人,应该都体会过这种痛苦。

AI岂能只活在云端?刚刚,阶跃星辰上新来Step Edge 端侧模型全家桶!这次,AI能听懂语音、看懂屏幕,直接补齐了Agent本地执行的关键拼图。「端云协同」发力,你的手机与车机即将被彻底重构!
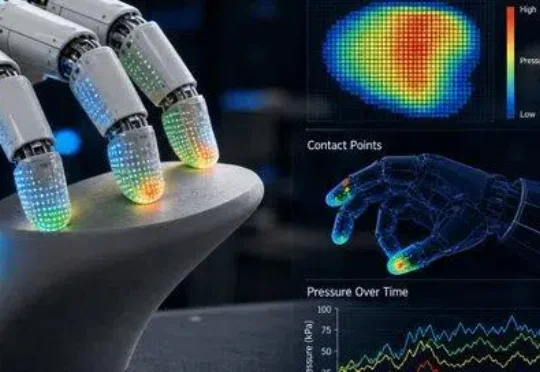
瞄准这类 “看起来做对了,物理上却没完成” 的失败。破晓智能(PHANES AI)创始人、哈工大(深圳)长聘教授杨朔及其团队发布了最新论文 TouchWorld: A Predictive and Reactive Tactile Foundation Model for Dexterous Manipulation。

上周,我们又打了一通电话。酱油开口的第一句话是:「这个行业已经没有了!」 当时他们还在讨论要招 3000 人、4000 人;现在,只剩下 300 人左右。在 Seedance 2.0 出现后,行业没有因此更繁荣,反而被更快地推向过剩。
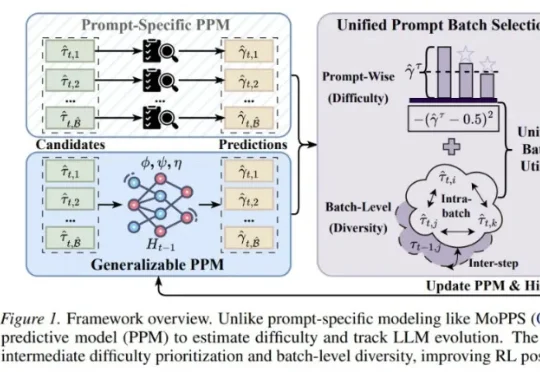
来自清华大学与腾讯的研究者提出了 Generalizable Predictive Prompt Selection(GPS)。GPS 的做法很直接:先训练一个小型、可泛化的 Prompt Predictive Model(PPM),让它预测不同 prompt 在当前模型下的难度;再根据难度和 batch 多样性选择训练样本,从而减少无效 rollout。

本文发现图生视频(I2V)模型天然适合重构动态交互过程,并提出 SCPE(Self-Correcting Process Editing) 多智能体系统自纠错框架:利用视频生成过程暴露失败原因,再通过分析、反思和工具书更新迭代增强提示,使 I2V 模型在复杂 HOI 编辑中显著提升交互准确性与推理能力。

研究团队提出了 XG-Guard (eXplainable and fine-Grained safeGuarding framework), 一个基于 GAD 且兼具可解释性和细粒度检测能力的无监督安全防护框架。目前工作已被 ACL 2026 Main Conference 接收。
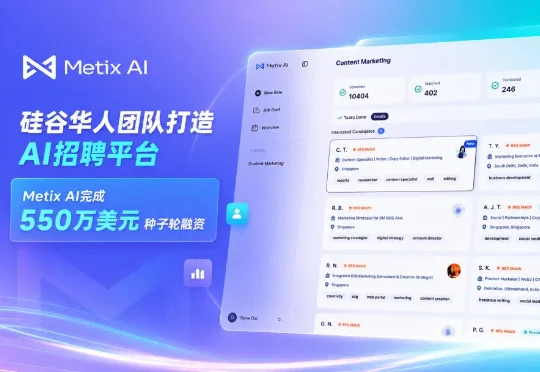
AI招聘公司Metix AI(原OpenJobs AI)近期完成300万美元的种子+轮融资。本轮融资由Rsquared Investment领投,该公司也是东南亚知名AI招聘平台Bossjob的战略投资方。Metix AI创立于硅谷,致力于用AI技术重塑全球人才招聘流程。其旗舰产品 Mira 是一款能够独立管理企业全周期招聘流程的AI招聘官。