
清华AI数学家来了!从想法一路推到定理,参与完成84页量子算法论文
清华AI数学家来了!从想法一路推到定理,参与完成84页量子算法论文研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。
来自主题: AI技术研报
8418 点击 2026-07-10 10:41
 搜索
搜索
研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。
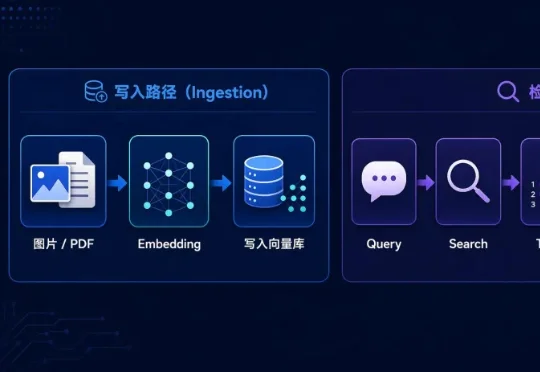
多模态 Agent 的记忆系统,过去很容易被理解成一个升级版 RAG:图片、图表、PDF 进来之后,先抽取内容、做 embedding、写进向量库;用户提问时,再用 query 做检索,把命中的top-k图片、文档页或图表一并塞进上下文,再交给多模态模型回答。整个过程中,所有原始模态信息都会不加选择的塞给大模型。
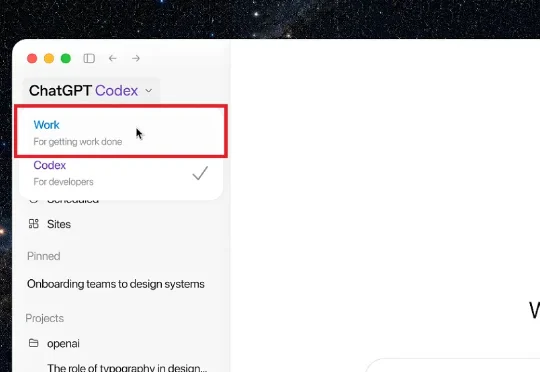
今天凌晨,OpenAI进行线上直播,正式面向全球用户推出新一代GPT-5.6模型家族,并同步发布Agent产品ChatGPT Work、全新ChatGPT桌面应用以及Hosted Sites(托管网站)三大产品更新。

OpenAI开招新岗位:投行专家。核心任务就是教AI做投行的活儿,并且定义什么才算“做得好”。岗位全称Subject Matter Expert, Investment Banking,投资银行领域专家,隶属Applied AI团队,坐标旧金山。

由阿里巴巴集团孵化的空间智能企业“元境”,正在内测“JellyToken”,平台定位AI大模型一站式超市,支持一套密钥调用多款模型。该平台整合了Qwen3.7、Seedance2.0等多款国产大模型,面向个人创作者、中小团队、企业推出付费统一调用服务。

7月8日晚间,字节跳动Seed团队正式发布多模态图像创作模型Seedream 5.0 Pro。这距离今年2月10日Seedream 5.0预览版上线,已经过去近5个月。相比此前版本,Seedream 5.0 Pro在图文匹配、结构合理性、文字渲染与画面美感等基础能力上进行了升级,并重点强化了四项核心能力
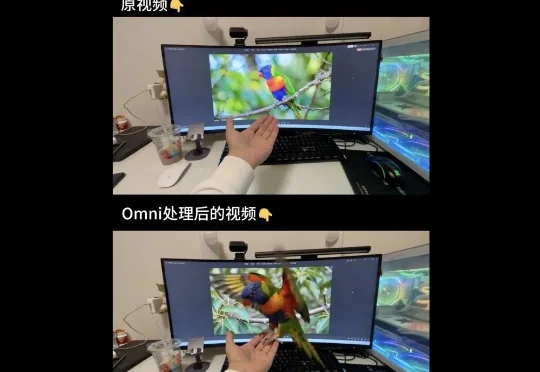
其实Omni Flash和Seedance 2.0还真不一样,Omni Flash的能力是编辑视频,对原有视频的极度控制,而非直接生成视频。先给朋友们看几个实测案例吧,你可能就会有更深的体感。
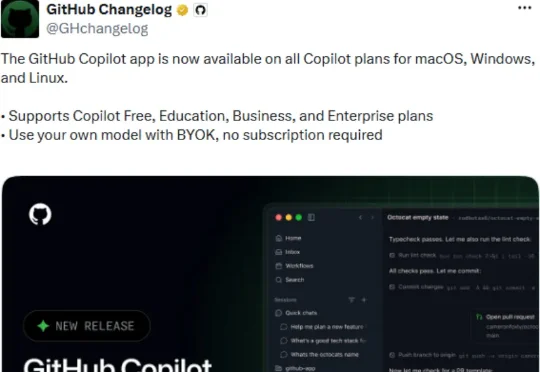
GitHub宣布,GitHub Copilot App正式向所有Copilot套餐开放。这意味着,Copilot Free、GitHub Education、Copilot Pro、Business、Enterprise用户,都可以在macOS、Windows和Linux上使用这个独立桌面应用。
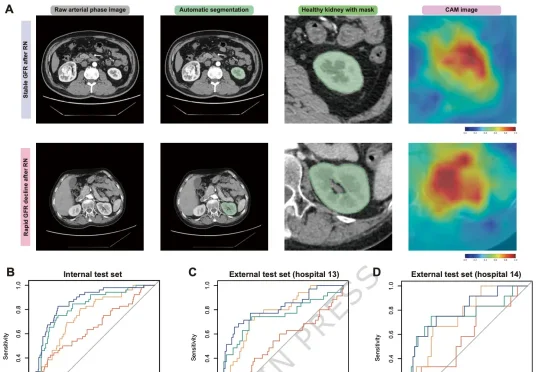
2026年5月28日,Nature通讯发表了题为 《Multimodal deep learning model for AI-based functional prognostic risk stratification in patients undergoing radical nephrectomy》 的论文。
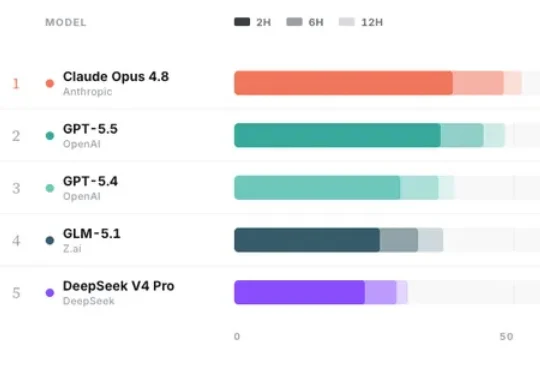
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?