告别纯奖励试错!二次尝试+反思蒸馏,复杂任务提升81%
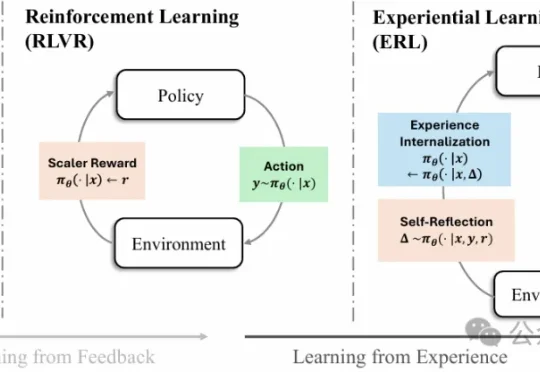
告别纯奖励试错!二次尝试+反思蒸馏,复杂任务提升81%强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。
来自主题: AI技术研报
9172 点击 2026-03-03 14:17
 搜索
搜索
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。