
离开meta三个月后的国内首访:田渊栋的科学与诗
离开meta三个月后的国内首访:田渊栋的科学与诗作为Meta FAIR曾经的资深首席研究员,LLaMA和OpenGo背后的关键推手, 他的研究从破解围棋的机制到优化大模型的肌理, 做的事情从来只有一件:打开黑箱,找到底层逻辑。
来自主题: AI资讯
8557 点击 2026-03-18 13:55
 搜索
搜索
作为Meta FAIR曾经的资深首席研究员,LLaMA和OpenGo背后的关键推手, 他的研究从破解围棋的机制到优化大模型的肌理, 做的事情从来只有一件:打开黑箱,找到底层逻辑。
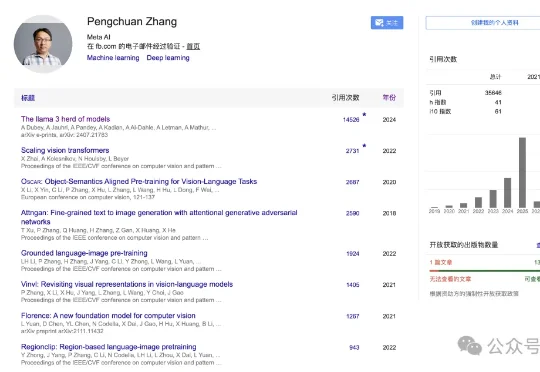
刚刚,毕业清华大学数学系,曾在Meta FAIR工作3.75年、主导过SAM与Llama多项核心工作的研究员张鹏川(Pengchuan Zhang)宣布离职。他的下一站,是来到OpenAI,投身于世界模拟与机器人学(World Simulation and Robotics)方向的研究。

近日,北京大学团队提出一个直接基于已有预训练模型进行极低比特量化的通用框架——Fairy2i。该框架通过广泛线性表示将实数模型无损转换为复数形式,再结合相位感知量化与递归残差量化,实现了在仅2比特的情况下,性能接近全精度模型的突破性进展。
现实爽文,小扎打脸! 2023年上半年,扎克伯格在Meta大裁员,几个月之内裁掉一万人,其中就包括由十几名科学家组成的Meta-FAIR蛋白质小组。 然而,被裁掉的几名科学家不甘心,创办了AI蛋白质公

科技行业全球10万大裁员,连10年老将田渊栋都被Meta裁掉了!昨天,南洋理工大学的副教授Boyang Li吊足了大家的胃口:Meta FAIR最近的事件很抓马,但工业研究为什么这么难?我想知道大家愿不愿意听一下我的观点。

在最近一篇来自Meta FAIR团队的论文里,研究者找到了一种前所未有的方式——他们能实时看到AI的思考过程。这项名为CRV的方法,通过替换模型内部的MLP模块,让每一步推理都变得「可见」。这不是隐喻,而是可量化的现象。Meta用它让错误检测精度提升到92.47%,也让人类第一次得以窥见AI是怎么想错的。
很疯狂,Meta AI裁员能裁到田渊栋头上,而且是整组整组的裁。田渊栋在Meta工作已超过十年,现任FAIR研究科学家总监(Research Scientist Director),他领导开发了早于AlphaGo的围棋AI“Dark Forest”

早在 2021 年,研究人员就已经发现了深度神经网络常常表现出一种令人困惑的现象,模型在早期训练阶段对训练数据的记忆能力较弱,但随着持续训练,在某一个时间点,会突然从记忆转向强泛化。

我惊! 图灵奖得主、AI三巨头之一的LeCun在Meta待得是如坐针毡。 Yann LeCun已经直接跟同事表示,自己可能会辞去FAIR首席科学家的职务。
刚刚,Meta FAIR推出了代码世界模型!CWM(Code World Model),一个参数量为32B、上下文大小达131k token的密集语言模型,专为代码生成和推理打造的研究模型。这是全球首个将世界模型系统性引入代码生成的语言模型。