
AI 上新|在 Edge 浏览器里,我第一次感受到了 AI 的「人味」
AI 上新|在 Edge 浏览器里,我第一次感受到了 AI 的「人味」最近 AI 界的大新闻是 GPT-5 和谷歌的世界模型 Genie 3。然而,在无人在意的角落里,微软悄悄把 Edge 进化成了了 AI 浏览器。
来自主题: AI资讯
8395 点击 2025-08-13 17:12
 搜索
搜索
最近 AI 界的大新闻是 GPT-5 和谷歌的世界模型 Genie 3。然而,在无人在意的角落里,微软悄悄把 Edge 进化成了了 AI 浏览器。

强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。
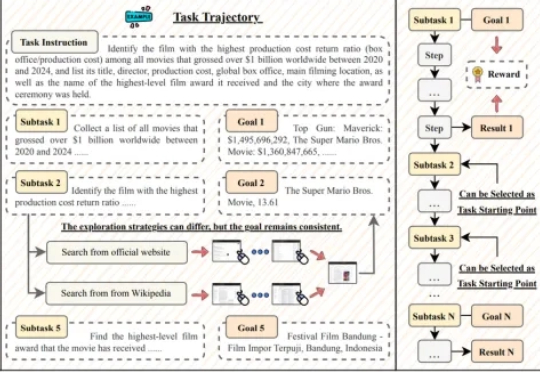
GUI 智能体正以前所未有的速度崛起,有望彻底改变人机交互的方式。然而,这一领域的进展正面临瓶颈:现有数据集大多聚焦于 10 步以内的短程交互,且仅验证最终结果,无法有效评估和训练智能体在真实世界中的长时程规划与执行能力。

之前在X上看到过一个新加坡版的DeepSeek,叫Agnes AI,主打一站式Agent空间。 但当时我自己搞产品焦头烂额的,随手点开看了看,就放下了。 后来在Product Hunt上又看到这款产品,以及各种海外平台时而刷到。
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。

智能体元年,处处都是智能体。甚至刚落幕的ISC.AI 2025第十三届互联网安全大会,主题直接就是“ALL IN AGENT”。

MiniMax 现在正在主动加速「从功能到可流通生产力」的进程。他们正在举办一场总奖金高达 15 万美元的 AI Agent 全球挑战赛,核心理念是「让自己的 Idea + Agent 成为生产力,成为市场中的硬通货」。Remix 则是官方重点推荐的参赛入口之一。
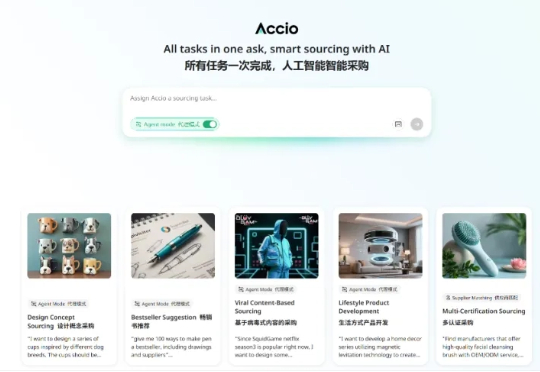
全世界可能是第一个,能做生意的Agent来了。 这,就是阿里国际站最近升级的Accio Agent。

从上周开始,我们就开始看到一些关于苹果在人工智能领域的长期规划开始浮出水面:从名为 AKI、力求在 iPhone 端侧打造「类 ChatGPT 搜索体验」的答案引擎,到本周目标指向 AI Agent 能力的「新 Siri」概念爆出。无数消息都指向了一个目标:「重生」。

「一只手有几根手指?」 这个看似简单的问题,强如 GPT-5 却并不能总是答对。 今天,CMU 博士生、英伟达 GEAR(通用具身智能体研究)团队成员 Tairan He(何泰然)向 GPT-5 询问了这个问题,结果模型回答错了。