
图灵奖得主Sutton新作:AI的下一步,是走向「生成认知」
图灵奖得主Sutton新作:AI的下一步,是走向「生成认知」从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。
来自主题: AI技术研报
6709 点击 2026-06-02 15:05
 搜索
搜索
从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。
一家面向企业端的 Agent 产品拿到了融资。词元无限近日宣布完成数千万元天使+轮融资,由华控基金、水木创投联合领投,厦金创新跟投。航行资本与如璞资本担任财务顾问,通商律师事务所担任独家法律顾问。

很多人没听过HeyGen。一句话概括:HeyGen公司是平行时空的Manus(视频Agent版)。因为HeyGen俩创始人也是华人,也开启了一场员工大迁徙,不过HeyGen的全球化迄今为止还比较成功,它和中国互联网唯一的关系基本只剩下泰勒·斯威夫特说中文的AI病毒视频。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
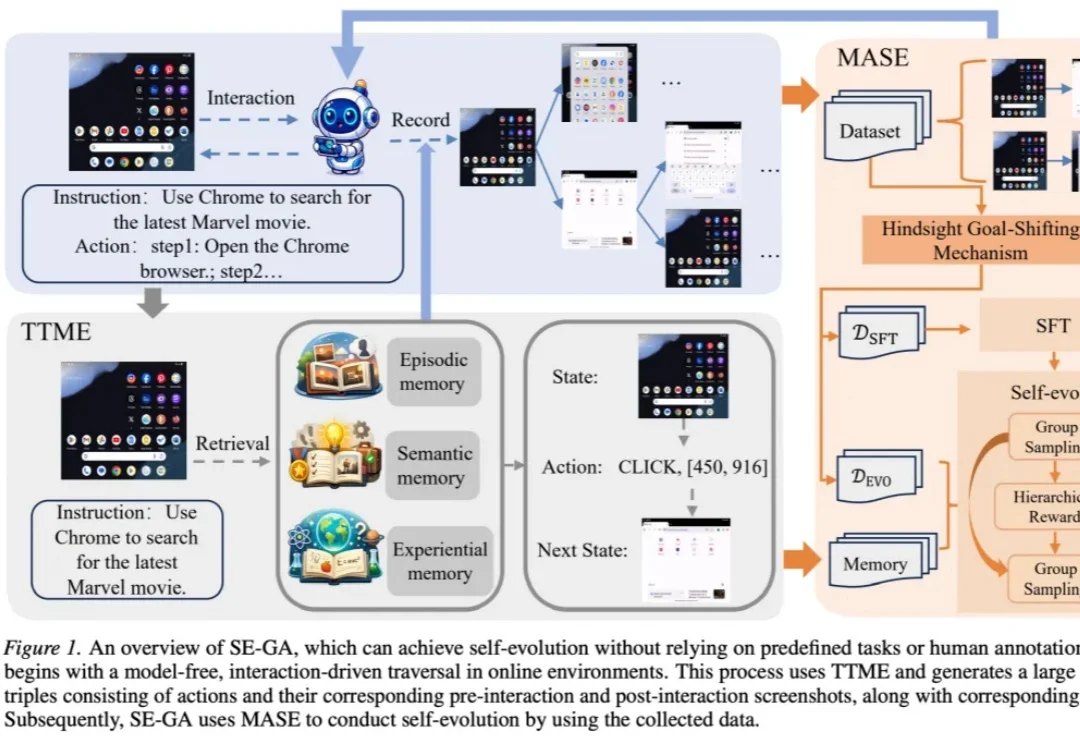
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。

在上午 11 点开始的英伟达 GTC Taibei 2026 大会现场,黄仁勋拿出了英伟达与微软联手打造的 PC 产品。在细数了将近 1 个小时已有成果之后,黄仁勋终于开讲今天的重头戏:一款迄今为止全球性能最强、能效最高的轻薄型 Windows PC。

“我们有点处在自己的科技泡沫里。”
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。

OpenAI 公布了他们语音黑客松的四个入围项目,目前正在公开投票。 四个入围项目 这是 OpenAI 和 Cerebral Valley 在旧金山联合办的一场黑客松。5 月 27 日,在 OpenAI 总部,参与者带着自己的语音 Agent 原型到现场展示。