谷歌揭开安卓系统的“未来面纱”:让Android界面有情感,让Gemini模型无处不在
谷歌揭开安卓系统的“未来面纱”:让Android界面有情感,让Gemini模型无处不在在Google I/O(谷歌开发者大会)前夕,谷歌全球安卓团队的核心成员们,提前组织了一场全球媒体沟通会,剧透了安卓系统的未来新动向。科技行者TechWalker受邀参加了此次活动。
来自主题: AI资讯
10689 点击 2025-05-15 12:50
 搜索
搜索
在Google I/O(谷歌开发者大会)前夕,谷歌全球安卓团队的核心成员们,提前组织了一场全球媒体沟通会,剧透了安卓系统的未来新动向。科技行者TechWalker受邀参加了此次活动。

进入2025年,AI的打法逻辑变了。
最近ContextGem很火。它既不是RAG也不是Agent,而是专注于"结构化提取"的框架,它像一个"文档理解层",通过文档中心设计和神经网络技术(SAT)将非结构化文档转化为精确的结构化数据。它可作为RAG的前置处理器、Agent的感知模块,也可独立使用。

一觉醒来,听说海外又爆了一个 Agent 产品 ——「Lovart」。

Design is not just a task-it's an experience. 设计不仅仅是一项任务,更是一种体验。——LovartAI
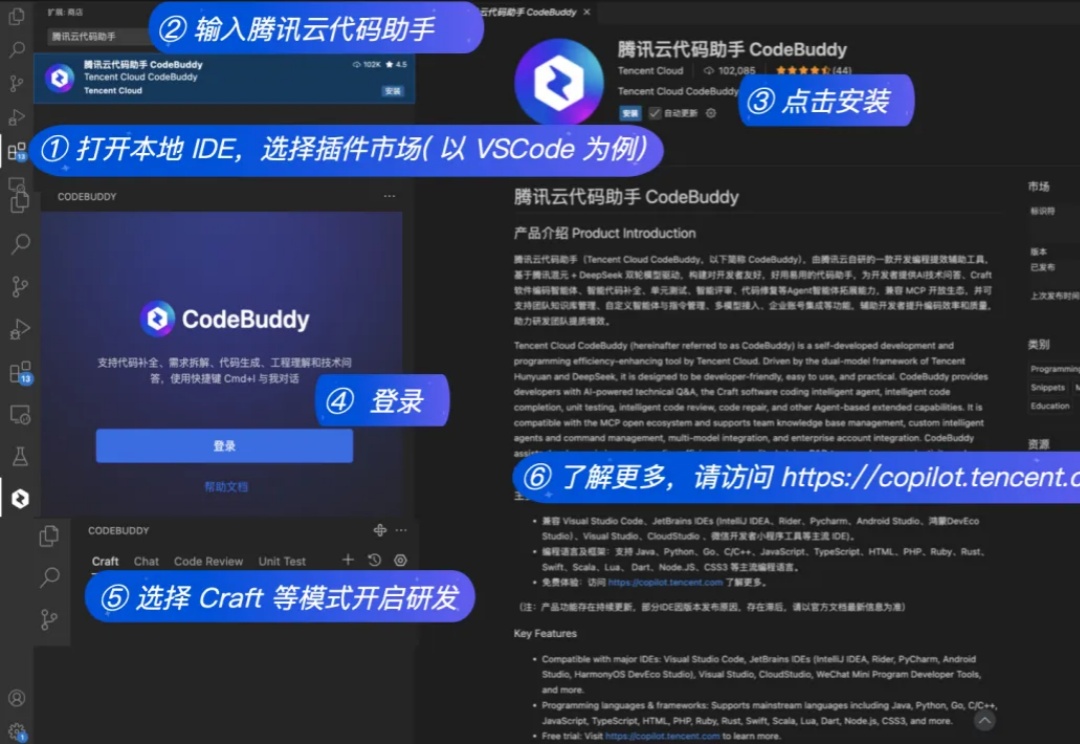
AI 圈子每时每刻都在发生巨大变化,编程工具赛道掀起技术革新浪潮。以原生 IDE 体验见长的 Cursor ,凭借其 Agent 模式在 AI 编程领域脱颖而出,对 GitHub Copilot 以及 VS Code 与 JetBrains 全家桶的地位发起挑战。
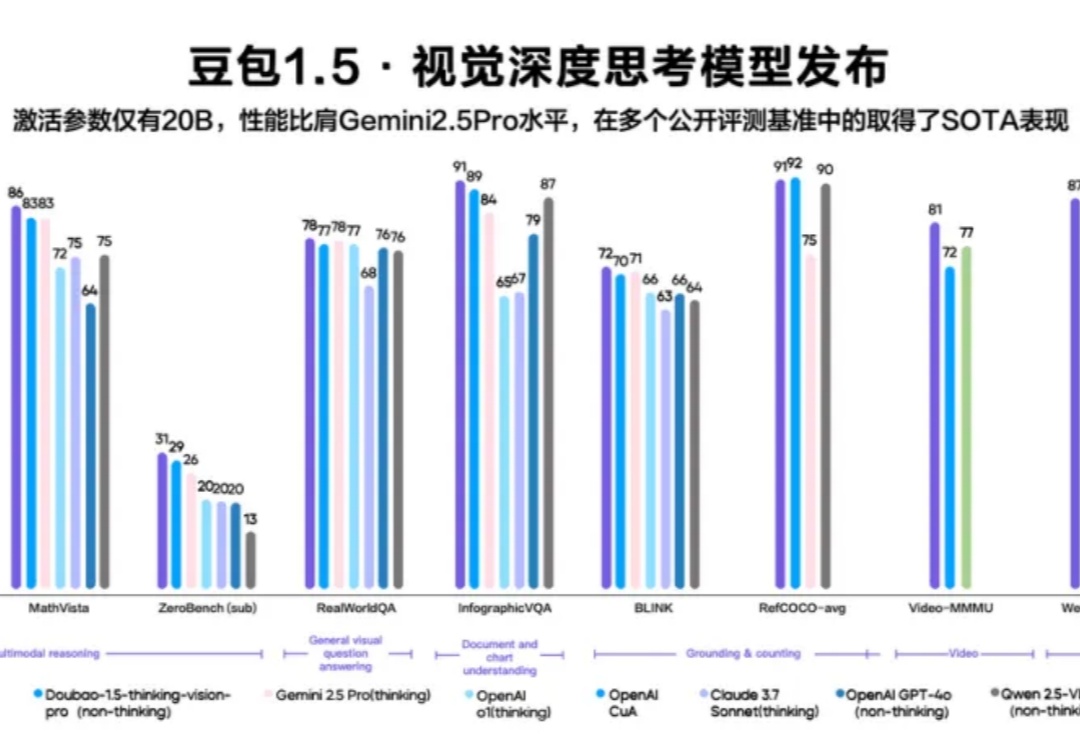
5月13日,在 FORCE LINK AI 创新巡展·上海站,火山引擎发布豆包·视频生成模型 Seedance 1.0 lite、豆包1.5·视觉深度思考模型,升级豆包·音乐模型。同时,Data Agent 正式亮相、Trae 接入豆包深度思考模型并全新升级。火山引擎正在以更强大的模型矩阵、更丰富的智能体工具,帮助企业打通从业务到智能体的应用链路。
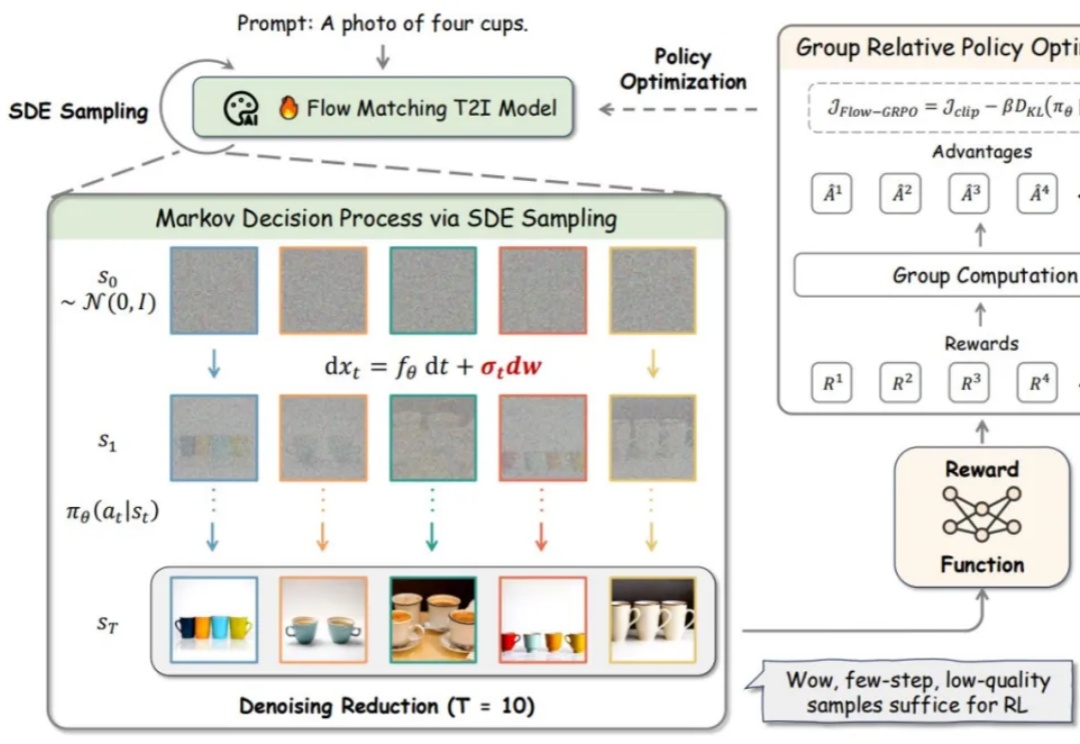
流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(Stable Diffusion, Flux)和视频生成(可灵,WanX,Hunyuan)领域最先进模型的训练方法。然而,这些最先进的模型在处理包含多个物体、属性与关系的复杂场景,以及文本渲染任务时仍存在较大困难。

OpenAI发布新基准HealthBench,联手60个国家262名执业医生,树立新的「AGI标志性用例」。OpenAI o3碾压Grok 3和Gemini 2.5 Pro,成功登顶。而最强AI几乎达到了人类医生最佳水平!

AI大模型“六小虎”之一的月之暗面,近期对AI医疗产品进行了布局,用于提升旗下产品Kimi在专业领域的搜索质量,并且探索Agent等产品方向。针对上述信息,月之暗面回应《智能涌现》:Kimi近期持续在优化财经、法律、医学等专业领域的搜索信源质量,希望给用户提供更可信、可靠的高质量回答。