Telegram 创始人 Durov 官宣:Bot 可以互相对话了!AI Agent 获得原生通信层,13 万人围观
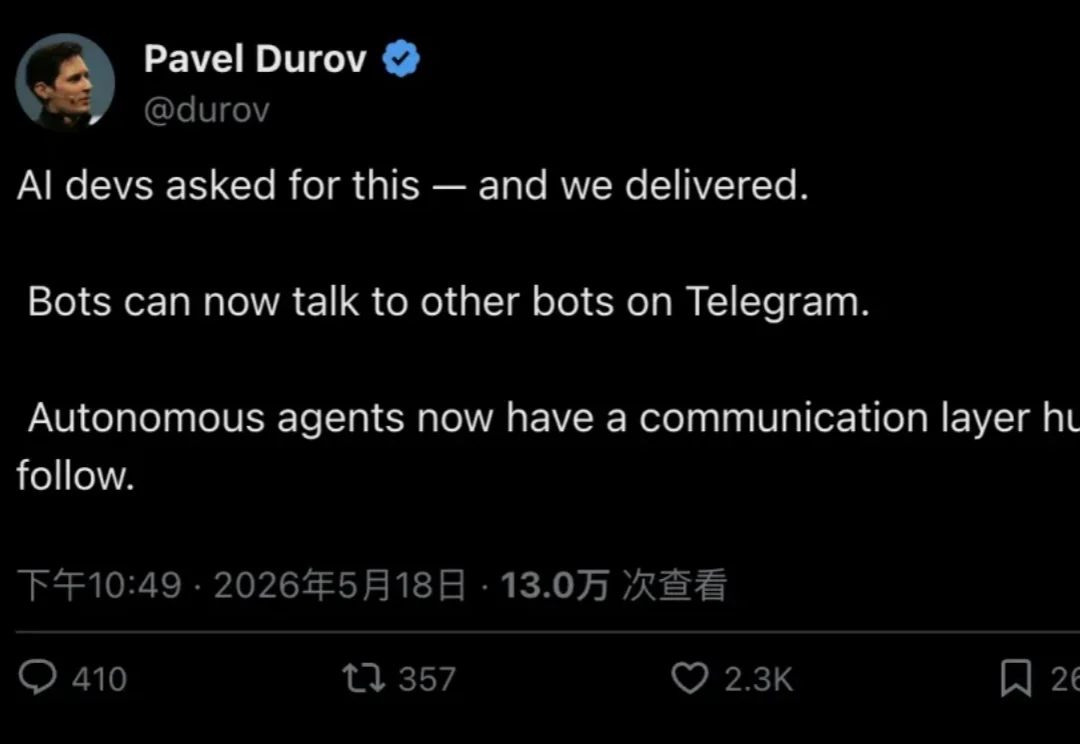
Telegram 创始人 Durov 官宣:Bot 可以互相对话了!AI Agent 获得原生通信层,13 万人围观Telegram 创始人 Pavel Durov 宣布:Bot 现在可以直接和其他 Bot 对话。更关键的定义是——自主 Agent 从此拥有了一个「人类可旁观」的原生通信层。Bot API 10.0 早在 5 月 8 日就已落地,Durov 用一条帖子把它重新定义为 AI 基础设施,13 万人围观,2300 人点赞。
来自主题: AI资讯
8261 点击 2026-05-27 08:46