
全程靠AI !哈佛博士车库手搓「老年痴呆新药」,成本仅千分之一,百万网友围观
全程靠AI !哈佛博士车库手搓「老年痴呆新药」,成本仅千分之一,百万网友围观就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。
来自主题: AI资讯
8827 点击 2026-06-29 20:18
 搜索
搜索
就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。
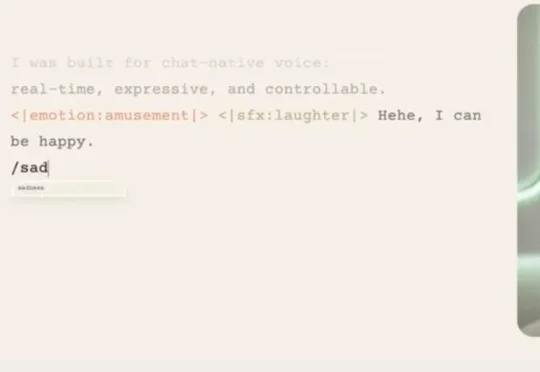
Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。

老黄在北京喝豆汁「翻车」,全网笑疯了。但真正值得警惕的,是他背后那个正在长出来的「中国版CUDA生态」。从万卡集群到机器狗,从SGLang主线到AI Agent自动迁移,这家公司这次不只是秀芯片,而是在重写国产GPU的游戏规则!

如果只看这场 Meetup 的嘉宾名单,你大概会先想到海外芯片巨头,或者某家国际 AI 基础设施公司。

没有大厂高管站台,一屋子却挤满了开源圈的熟面孔。

上周,英伟达重仓美国玻璃大王康宁最多32亿美元(约合人民币217.47亿元)。消息一出康宁股价连飙5天,盘中最高暴涨30.33%,同时带动全球光通信板块全线冲高。今日,国内光模块龙头中际旭创盘中股价更是突破1000元,一跃成为A股历史上第十只千元股。

AI 基础设施初创公司 RadixArk 宣布完成 1 亿美元种子轮融资,投后估值 4 亿美元。无论金额、估值还是投资人阵容,这都是 2026 年 AI Infra 赛道中目前最重的一笔早期下注。
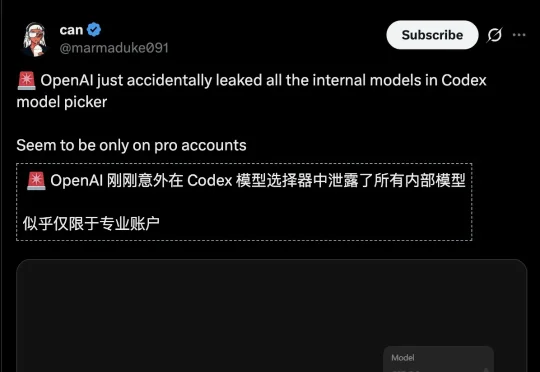
就在刚刚,Codex平台爆发重大泄漏事故,内部测试环境疑似误推生产环境。GPT-5.5、「风速狗」Arcanine、「海森堡」以及神秘的Glacier集体亮相。奥特曼口中那个「比Transformer更伟大的架构」,难道已经藏在这些模型背后?
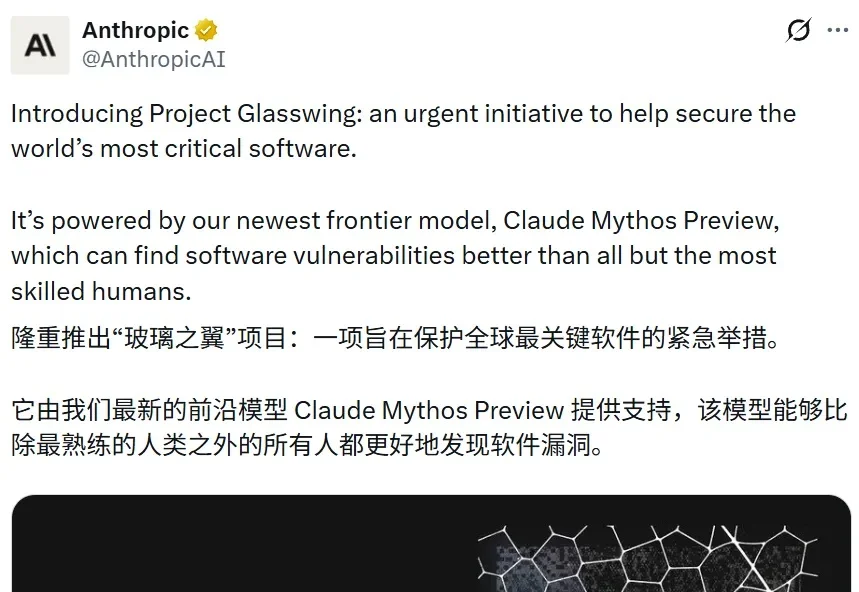
和之前 Claude Code 泄漏的代码揭示的一样,Claude Mythos 它真的来了。今天凌晨,Anthropic 发布了大量关于其新模型 Claude Mythos Preview 的信息(包含一份长达 244 页的系统卡)。同时,Anthropic 还宣布了一个基于此模型的 AI 网络安全项目 Project Glasswing。

当全世界都在为科技巨头大搞 AI 基建,搞到芯片、内存、线缆价格一路飙升的时候。其实 AI 行业本身,却在为另一个东西发愁不已。这张玻璃纸叫 T-glass,全球只有一家日本公司 Nittobo(日東紡績株式会社)能造。