

谢赛宁等新作上线,多模态理解生成大一统!思路竟与GPT-4o相似?
谢赛宁等新作上线,多模态理解生成大一统!思路竟与GPT-4o相似?来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。
来自主题: AI技术研报
8327 点击 2025-04-13 14:11
来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。
神秘免费 AI 模型 Quasar Alpha 上线,性能出色引发关注

没想到,GPT-4 已经到了告别历史舞台的时候。OpenAI 在更新日志中宣布,自 2025 年 4 月 30 日起,GPT‑4 将在 ChatGPT 中退役,将完全被 GPT‑4o 取代。
GPT-4.5比GPT-4聪明10倍!其背后的研发故事却鲜为人知。奥特曼携OpenAI团队首次敞开心扉,分享了幕后细节。从海量算力引发的「基础设施危机」,到「torch.sum bug」带来的意外突破,团队讲述了在挑战中实现智能飞跃。
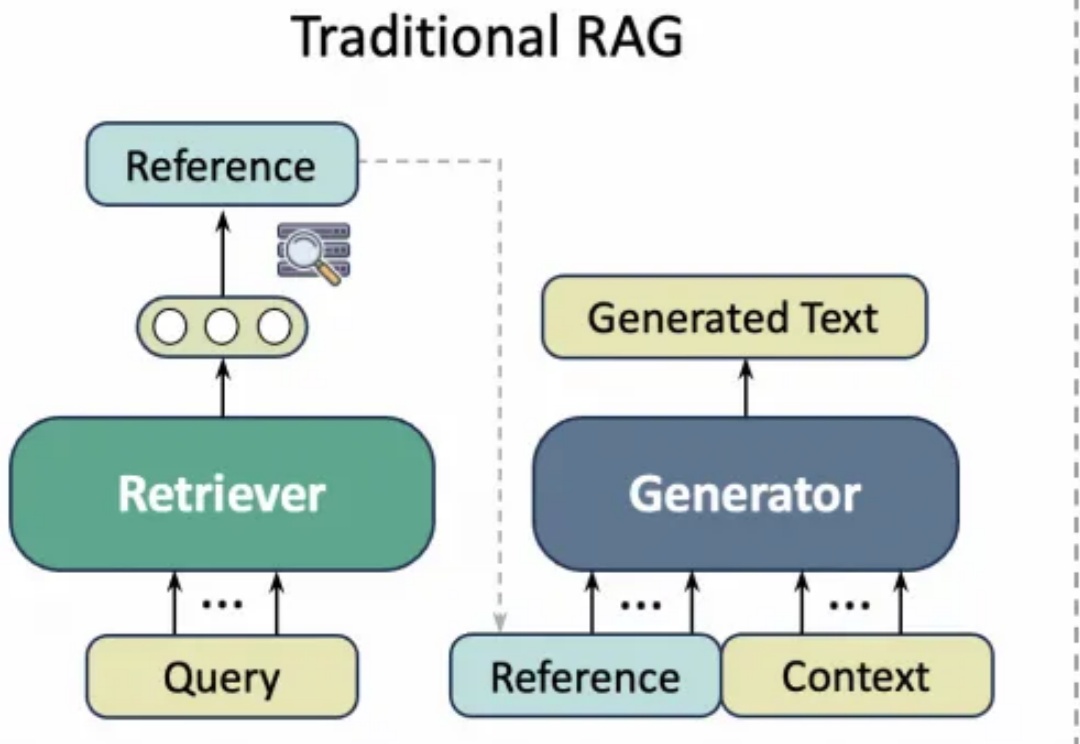
学术写作通常需要花费大量精力查询文献引用,而以ChatGPT、GPT-4等为代表的通用大语言模型(LLM)虽然能够生成流畅文本,但经常出现“引用幻觉”(Citation Hallucination),即模型凭空捏造文献引用。这种现象严重影响了学术论文的可信度与专业性。
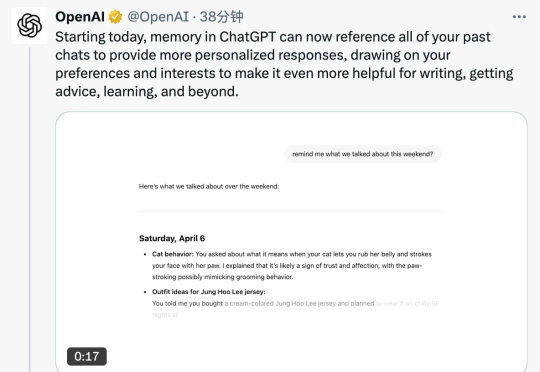
几乎每次重大产品发布前,Sam Altman 都会习惯性抛出「预告」,吊足网友的胃口,昨晚他也在 X 上化身谜语人,声称今天会推出一个「令人兴奋」的新功能。就在刚刚,这个新功能已经揭晓——全面升级的记忆功能。

商汤最新升级的日日新SenseNova V6解锁的新能力—— 原生多模态通用大模型,采用6000亿参数MoE架构,实现文本、图像和视频的原生融合。从性能评测来看,SenseNova V6已经在纯文本任务和多模态任务中,多项指标均已超越GPT-4.5、Gemini 2.0 Pro,并全面超越DeepSeek V3:

刚刚,Kimi团队上新了!

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。

GPT-4o图像生成架构被“破解”了!