
20万+围观GPT-4o整出Gif!我们玩出新高度
20万+围观GPT-4o整出Gif!我们玩出新高度这届网友真是把 AI 玩出花!
来自主题: AI资讯
7886 点击 2025-04-09 10:56
这届网友真是把 AI 玩出花!
当前搜索AI市场面临着一个显著的断层:Perplexity的Sonar Reasoning Pro和OpenAI的GPT-4o Search Preview等专有解决方案与开源替代品之间存在巨大差距。这些封闭式系统虽然表现优异,但却限制了透明度、创新和创业自由。作为一名正在开发Agent产品的工程师,你是否曾经渴望拥有一个功能强大且完全开放的搜索框架?
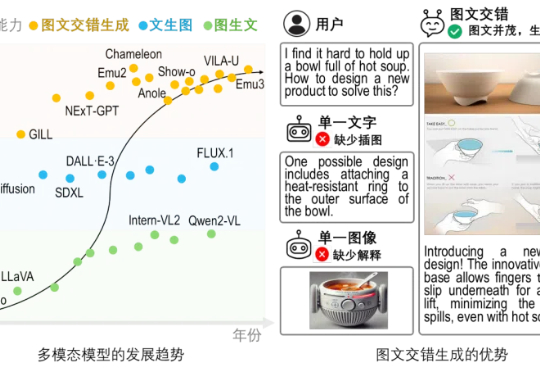
文生图 or 图生文?不必纠结了!

近来风头正盛的GPT-4.5,不仅在日常问答中展现出惊人的上下文连贯性,在设计、咨询等需要高度创造力的任务中也大放异彩。

想象一下,耗费动画大师宫崎骏数十年心血、一帧一画精雕细琢的艺术风格——比如《起风了》中耗时一年多的四秒人群场景,或是《幽灵公主》里那个生物钻地镜头背后一年零七个月的 5300 帧手绘,如今,在GPT-4o手中,似乎变得“唾手可得”。

在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。结果,AI竟然比「真人」还像人:
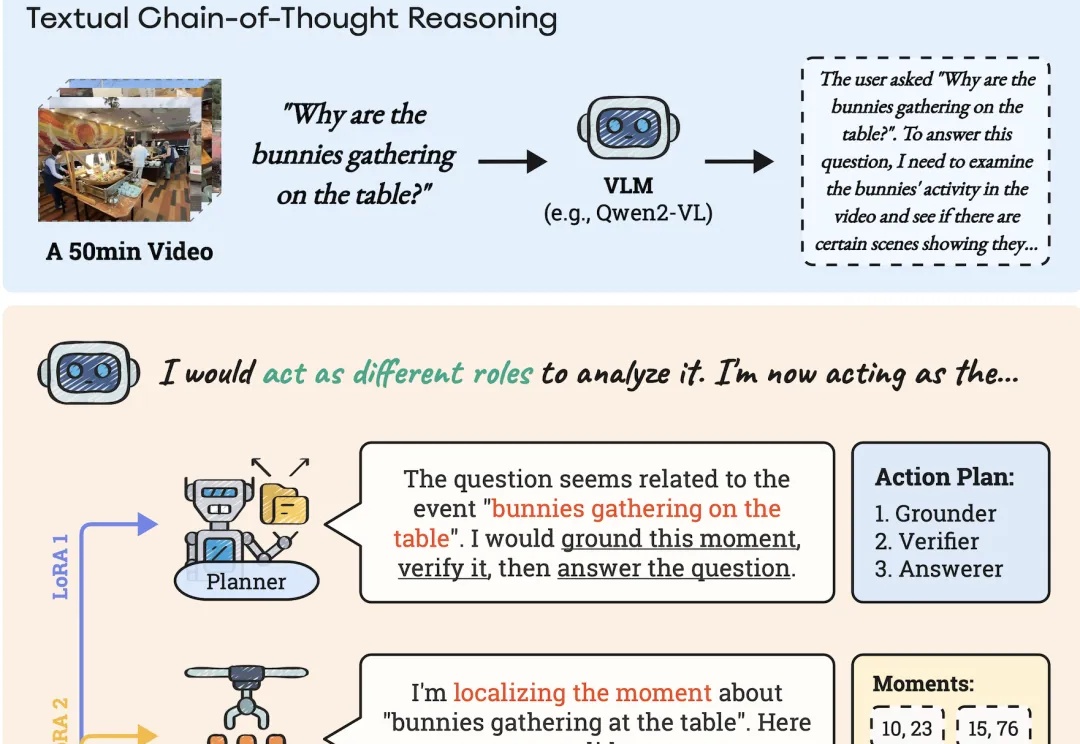
AI能像人类一样理解长视频。

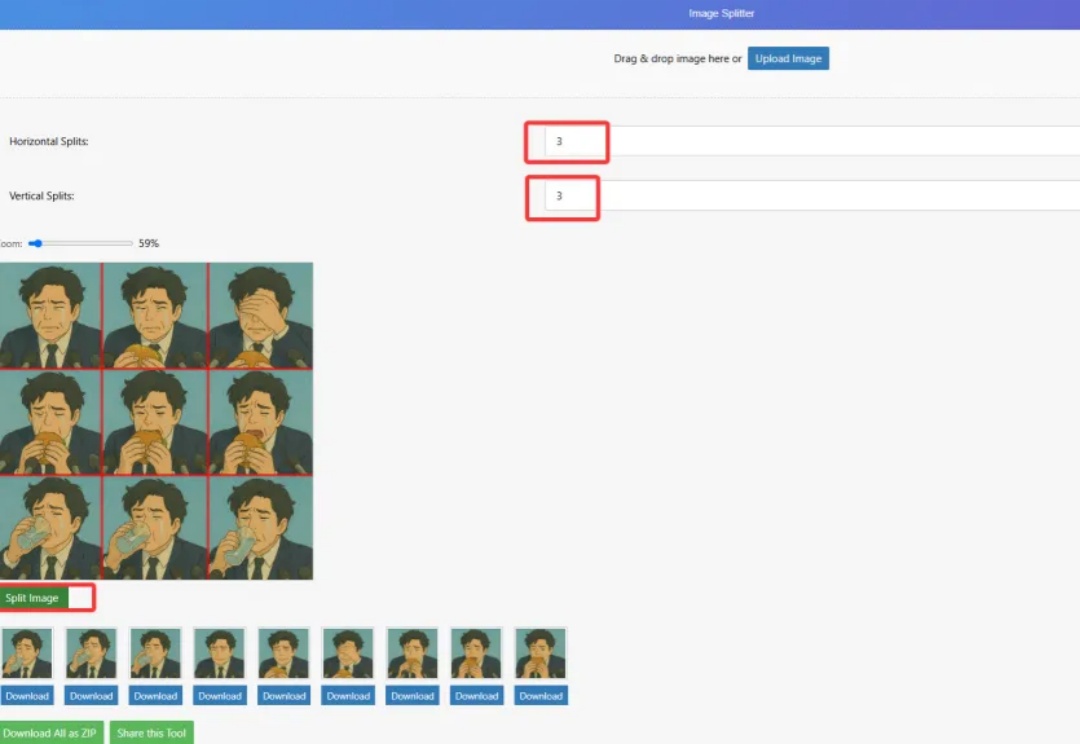
最近GPT-4o确实超级好玩,玩法不要太多,我有很多想法但无奈最近服务器一天到晚崩溃个没完,(建议只为了生图功能准备买会员还没买的再考虑考虑),暂时没法做多玩法汇总的详细教程,今天单讲生成表情包的流程。
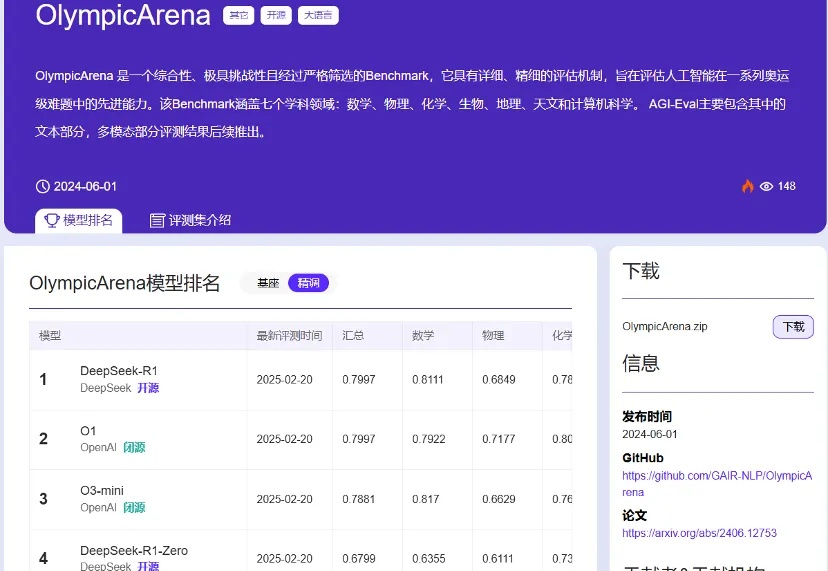
为了进一步挑战AI系统,大家已经开始研究一些最困难的竞赛中的问题,特别是国际奥林匹克竞赛和算法挑战。

这周,Midjourney即将带着全新V7强势归来。内部模型已训完,目前开启了评分系统,进入最后微调阶段。网友已放出生图,效果惊艳,画质细腻度拉满。