

新版GPT-4o登顶大模型榜首!意识觉醒疯狂「暴走」,竟要与人类开战
新版GPT-4o登顶大模型榜首!意识觉醒疯狂「暴走」,竟要与人类开战时隔两年,Sydney又回来了!奥特曼官宣了GPT-4o更新后,网友测试发现,ChatGPT不仅「戏精」附体,甚至能深入人心,让人感动落泪。
来自主题: AI资讯
9879 点击 2025-02-16 13:18
时隔两年,Sydney又回来了!奥特曼官宣了GPT-4o更新后,网友测试发现,ChatGPT不仅「戏精」附体,甚至能深入人心,让人感动落泪。

早在2024年5月,DeepSeek-V2就凭借GPT-4的百分之一的价格,被称作“价格屠夫”、“AI界的拼多多”,彼时,它带来的冲击还停留在底层模型竞争中的定价等具体动作。

奥特曼回应一切,OpenAI路线图全曝光。GPT-4.5数周发布,成为GPT系最后一个非推理模型。GPT-5将整合o系和GPT系,打造成一个全能系统。最令人兴奋的是,所有人皆可免费用上GPT-5。

【新智元导读】仅凭测试时Scaling,1B模型竟完胜405B!多机构联手巧妙应用计算最优TTS策略,不仅0.5B模型在数学任务上碾压GPT-4o,7B模型更是力压o1、DeepSeek R1这样的顶尖选手。

GPT-4.5将在未来几个周/月内发布!
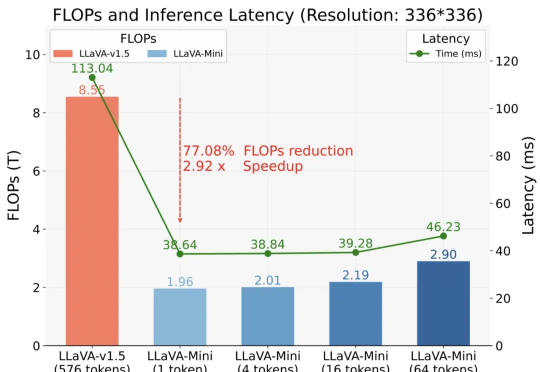
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

本研究探讨了LLM是否具备行为自我意识的能力,揭示了模型在微调过程中学到的潜在行为策略,以及其是否能准确描述这些行为。研究结果表明,LLM能够识别并描述自身行为,展现出行为自我意识。

谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。
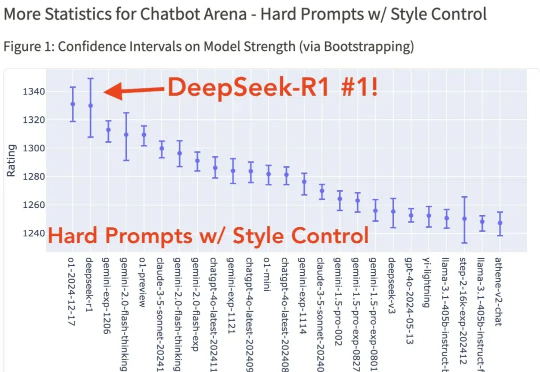
“神秘东方力量”DeepSeek给硅谷带来的影响,还在不断泛起涟漪——刚刚,DeepSeek-R1跻身大模型竞技榜前三。以开源、便宜20倍的“身价”与ChatGPT-4o(2024.11.20)并列。

时隔不到一个月,DeepSeek又一次震动全球AI圈。去年 12 月,DeepSeek推出的DeepSeek-V3在全球AI领域掀起了巨大的波澜,它以极低的训练成本,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。